Draw Call 对于是性能优化过程需要关注的一个重要的内容。
简介
- 为了在屏幕上进行绘制,Unity 会发起 Draw Call 调用。每个 Draw Call 会告诉图形 API 要绘制什么内容以及用什么方式绘制。
- 每个 Draw Call 都包含图形 API 在屏幕上绘制所需的所有信息,例如有关纹理的信息、着色器和缓冲区。比起 Draw Call 的调用, Draw Call 的准备工作通常更消耗资源。
- 为了准备 Draw Call ,CPU 设置资源并更改 GPU 上的内部设置,这些设置统称为渲染状态。渲染状态的更改(例如切换到不同的材质)是图形 API 执行的最消耗资源的操作。
- 更改渲染状态是资源密集型任务,需要消耗大量的硬件资源。如果要优化渲染性能,主要需要减少渲染状态更改的次数。通过对相同渲染状态的对象进行分组,则图形 API 可以使用相同的渲染对象来执行多个 Draw Call ,而不需要同样数量的渲染状态更改。
合批
- 通过合并网格来减少 draw call ,需要满足以下条件:
- 仅支持 MeshRenderer 、TrailRenderer 、LineRenderer 、ParticleSystem 、SpriteRenderer ,其他不支持,如:SkinnedMeshRender Cloth 。
- Renderer 组件类型相同的对象才能进行合批。
- 需要使用相同的材质球。
- Unity 提供了两种合批方式:
- 静态合批。
- 动态合批。
- 合批的优点,是 Unity 在绘制过程中,可以单独剔除部分网格对象,但代价是会产生一些额外开销。
- 在内置渲染管道中,可以使用 MaterialPropertyBlock 更改材质属性,而不会破坏绘制调用批处理。尽管 CPU 仍然需要进行一些渲染状态更改,但使用 MaterialPropertyBlock 比使用多种材质更快。
- 半透明的队列,通常需要 Unity 按照从后到前的顺序渲染网格。要批量处理透明网格,Unity 首先按从后到前的顺序进行排列,然后尝试合批。由于 Unity 必须按从后到前的顺序渲染网格,因此它通常无法批量处理与不透明网格一样多的半透明网格。
静态合批
- 官方文档说明如下:
- 静态合批预先组合静态游戏对象的网格, Unity 将组合数据发送到 GPU,但单独渲染组合中的每个网格。 Unity 仍然可以单独剔除网格,但每次绘制调用所占用的资源较少,因为数据的状态永远不会改变。
- 静态合批的对象需要满足以下条件:
- 要为 active 状态。
- 具有 MeshFilter 组件并且为 enable 状态。
- MeshFilter 组件上有设置网格。
- 网格需要开启 read/write 状态。
- 网格顶点数量大于 0 。
- 网格没有合并过。
- 具有 MeshRenderer 组件并且为 enable 状态。
- MeshRender 使用的所有材质球的 shader 没有开启 DisableBatching 标签。
- 静态合批会为每个对象创建一个网格,将所有网格组合成一个新的大网格,再应用到所有合批的对象上,因此会需要额外的 CPU 内存,如果是离线处理,还会占用更多的存储空间。因此,对于大量使用相同网格的对象,使用静态合批可能会产生较大的内存问题。
- 静态合批每个批次最多可以包含 64000 个顶点,超出时会创建一个新的批次。
不透明物体(Geometry)
- 创建 10 个网格和 GameObject ,在不透明队列(Geometry)中渲染。运行时,根据静态合批的网格的 submeshes 顺序,对 GameObject 进行排序,第一个 submesh 离相机最近,如图所示:
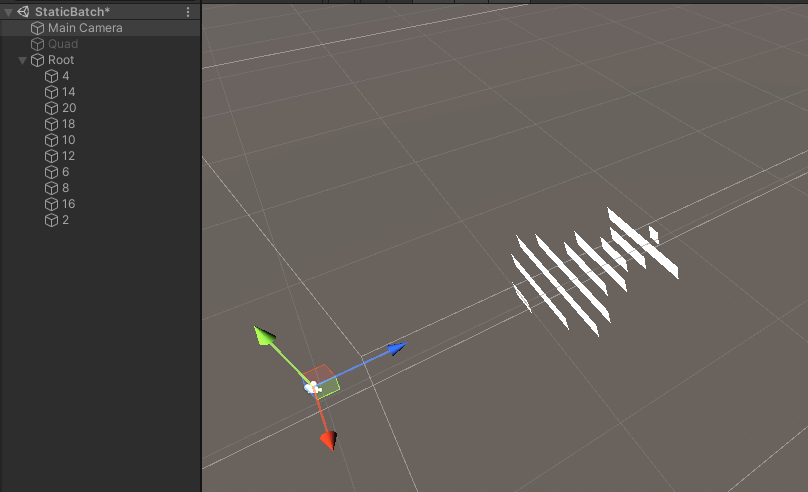

- 运行时表现如下:
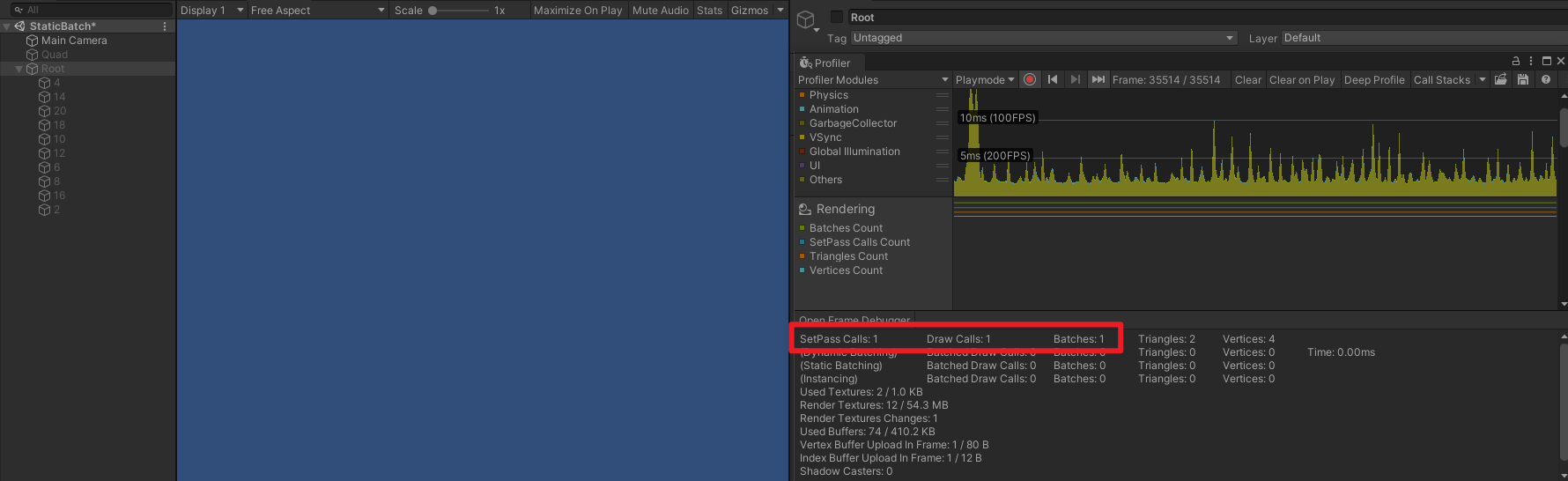
- 可以看到,静态合批后, SetPass Call 、Draw Call 、Batch 从 1 变成了 2,即创建的 GameObject 产生的 SetPass Call 、Draw Call 、Batch 都只有 1 。
- 重新对 GameObject 进行排序,调整成和 submeshes 的顺序不同,如:
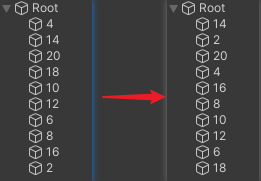
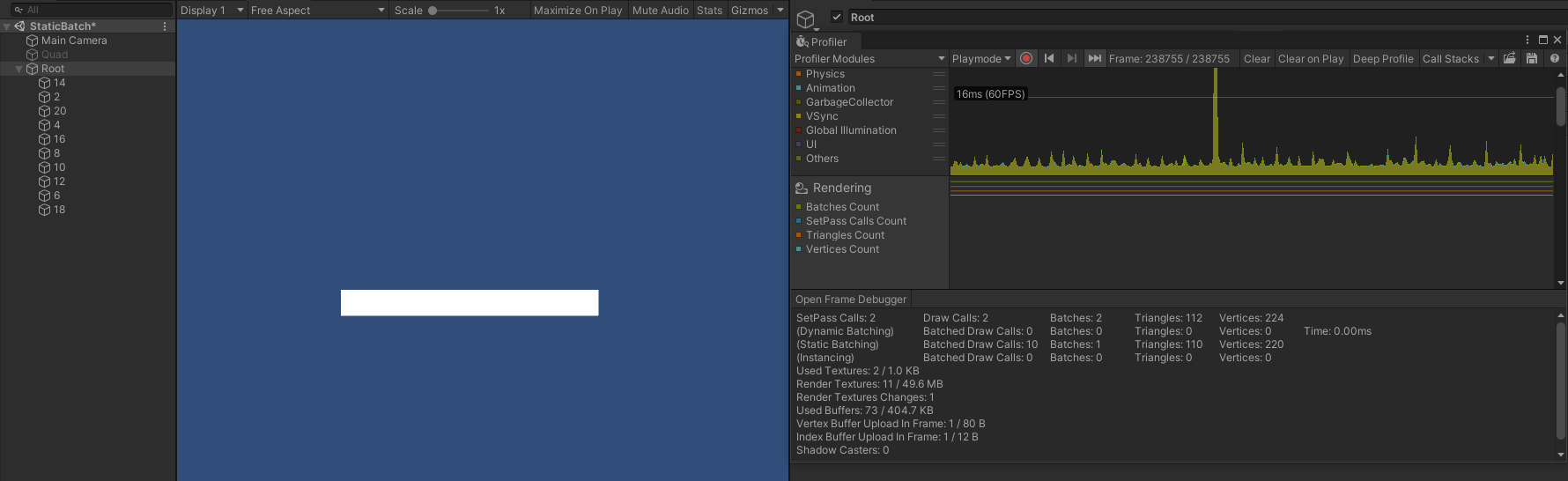
- 此时,SetPass Call 、Draw Call 、Batch 仍然为 2 ,即不会受到深度的影响。
- 分别隐藏 submeshes 的首个对象(4)、前两个对象(4 、14)、前两个对象和最后一个对象(4 、14 、2)时,SetPass Call 、Draw Call 、Batch 同样不会发生变化。
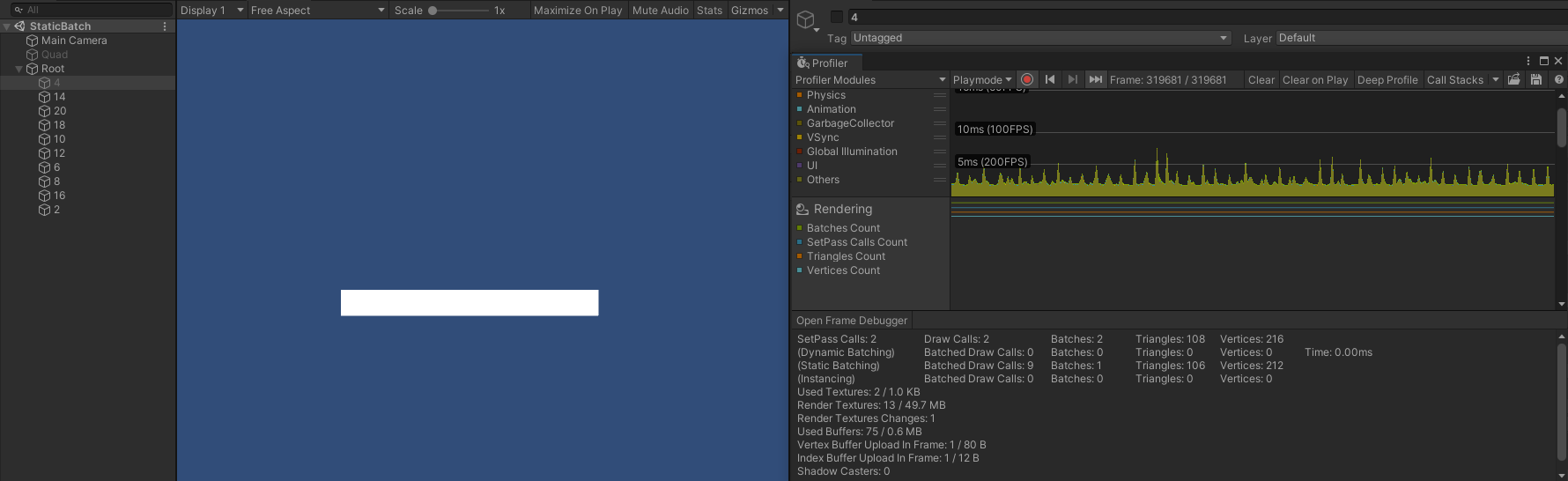
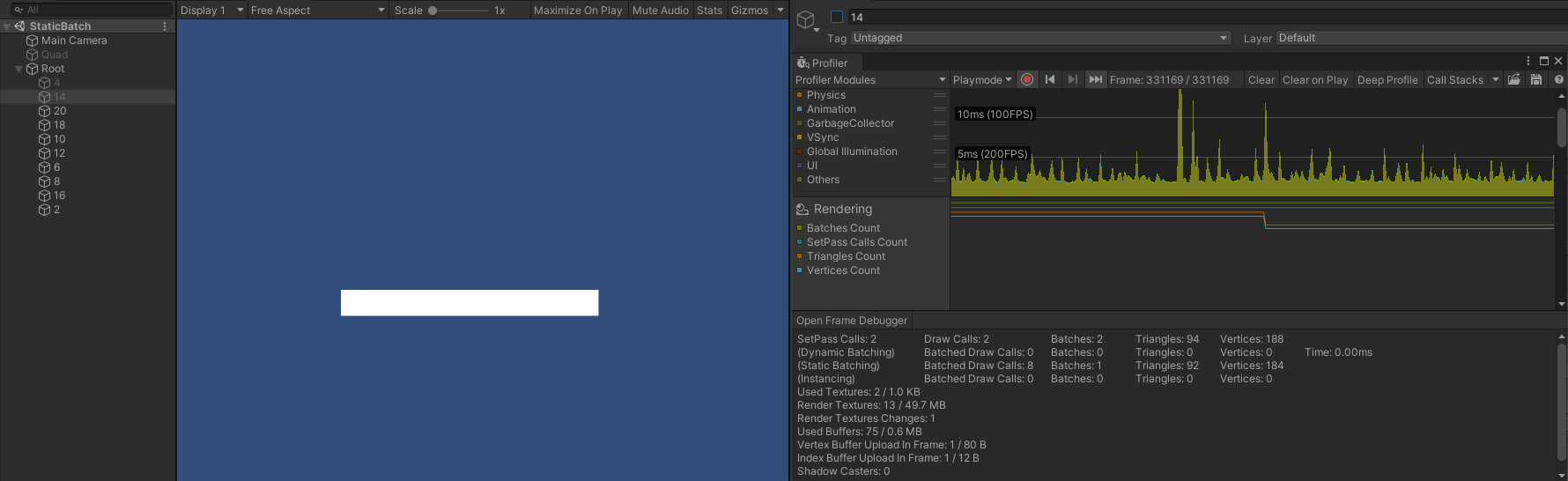
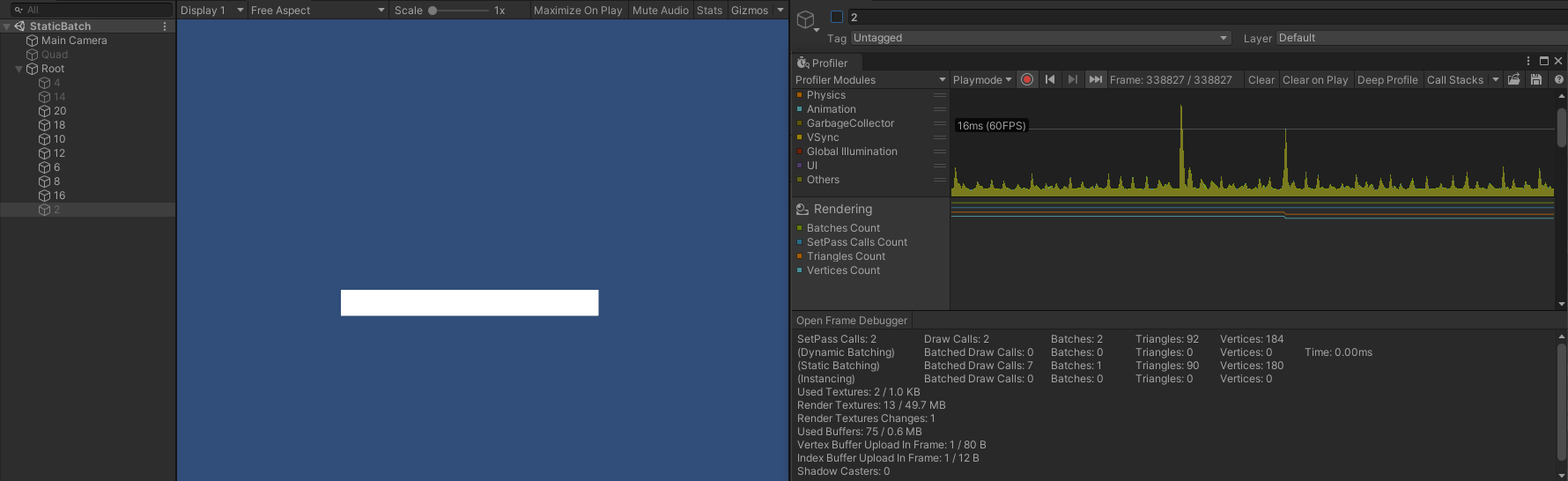
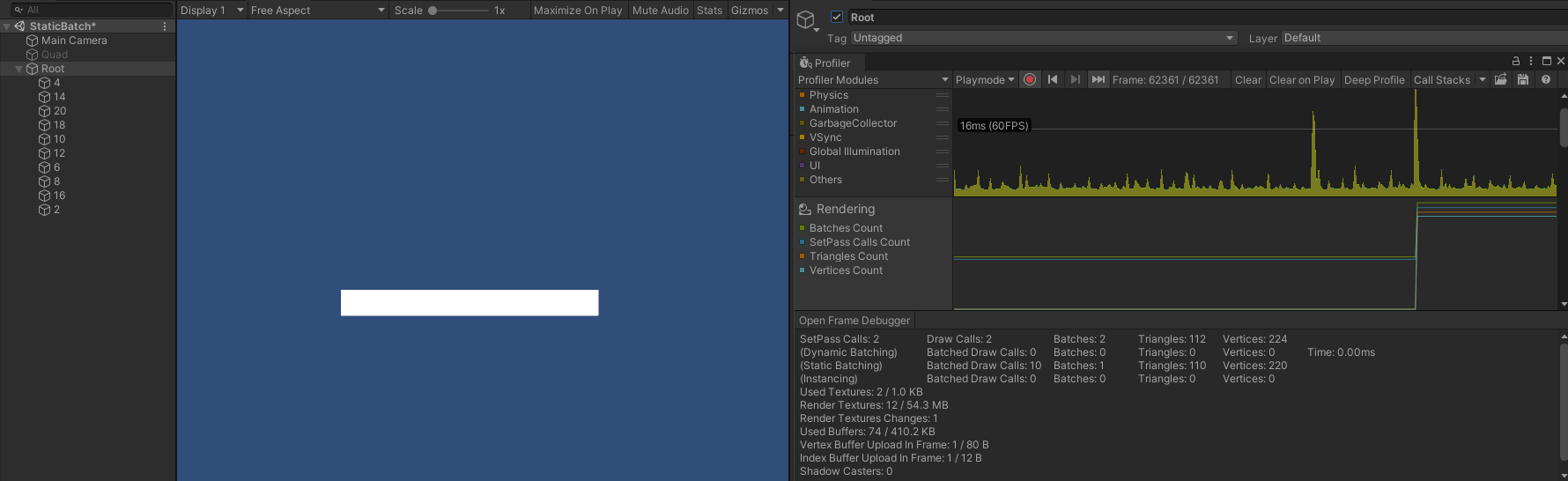
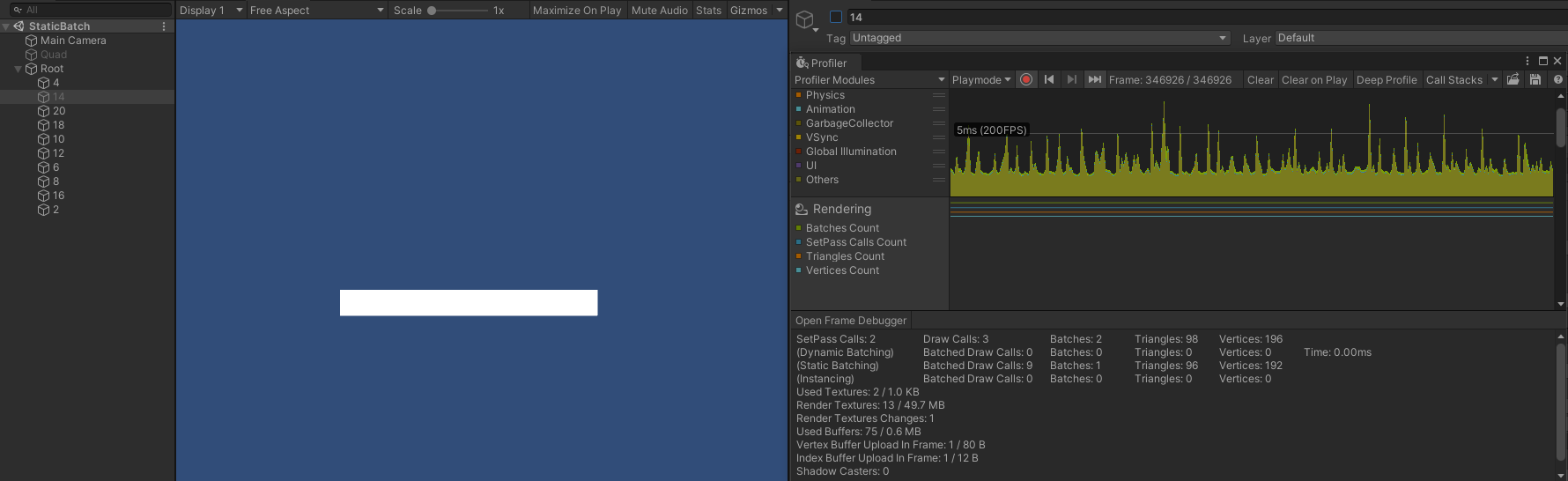
- 只隐藏第二个对象(14)时,SetPass Call 、Batch 仍然为 2 ,而此时 Draw Call 则变成了 3 ,此时渲染顺序为:
- 第一个对象(4)。
- 第三到第十个对象(20 、18 、10 、12 、6 、8 、16 、2)。
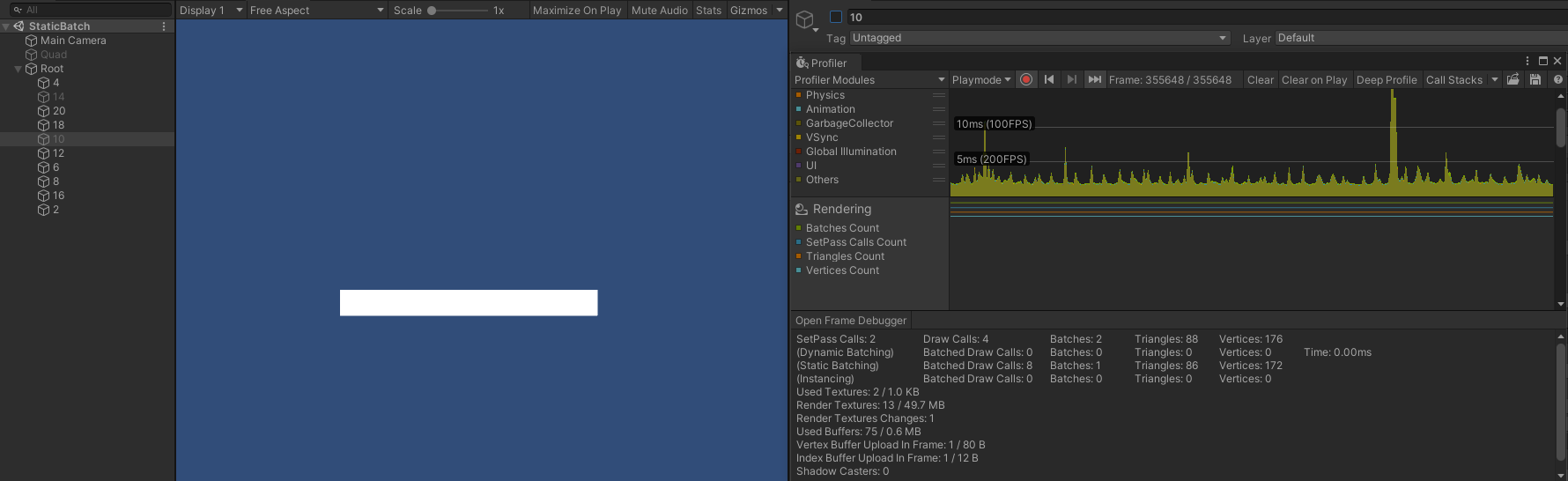
- 隐藏第二、第五个对象(14 、10)时, Draw Call 则变成了 4 ,此时渲染顺序为:
- 第一个对象(4)。
- 第三、第四个对象(20 、18)。
- 第六到第十个对象(12 、6 、8 、16 、2)。
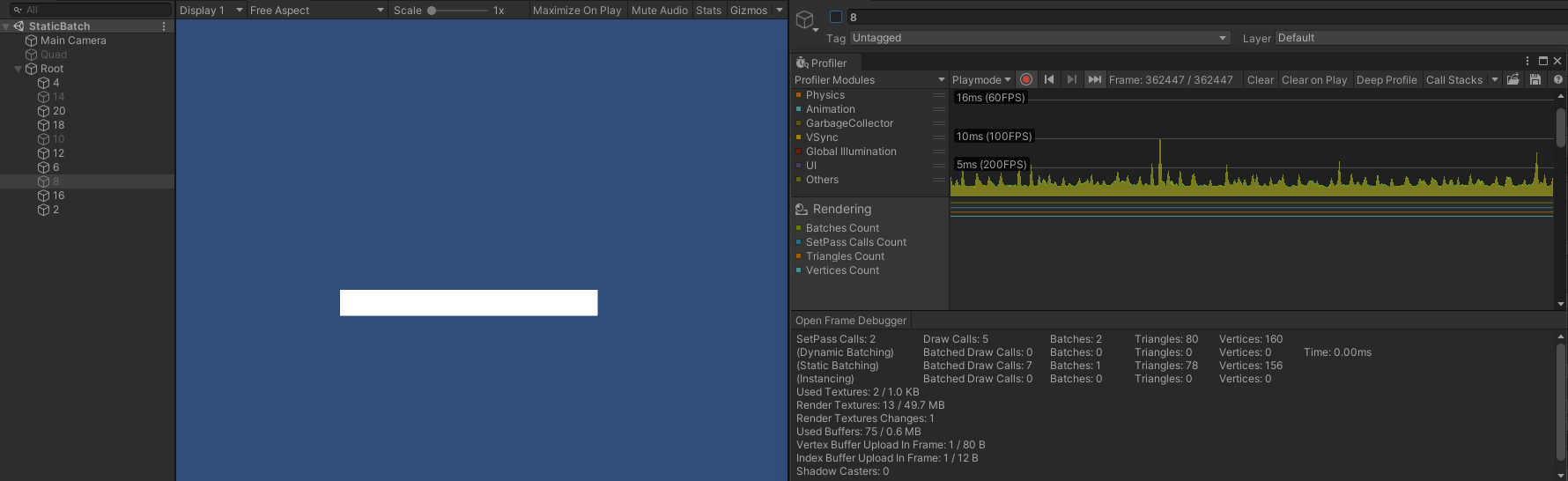
- 隐藏第二、第五、第八个对象(14 、10 、8)时, Draw Call 则变成了 5 ,此时渲染顺序为:
- 第一个对象(4)。
- 第三、第四个对象(20 、18)。
- 第六、第七个对象(12 、6)。
- 第九、第十个对象(16 、2)。
- 也就是说,对于不透明的物体,静态合批合并后的网格渲染时,SetPass Call 、Batch 都能进行合并,而 Draw Call 则不一定。如果需要渲染的对象在 submeshes 中是连续的,则可以使用 1 个 Draw Call 进行绘制,而如果隐藏了某些对象导致不连续,最终分成几段则需要几个 Draw Call 。
半透明物体(Transparent)
- 将物体改成半透明队列(Transparent)中渲染时,如图所示:
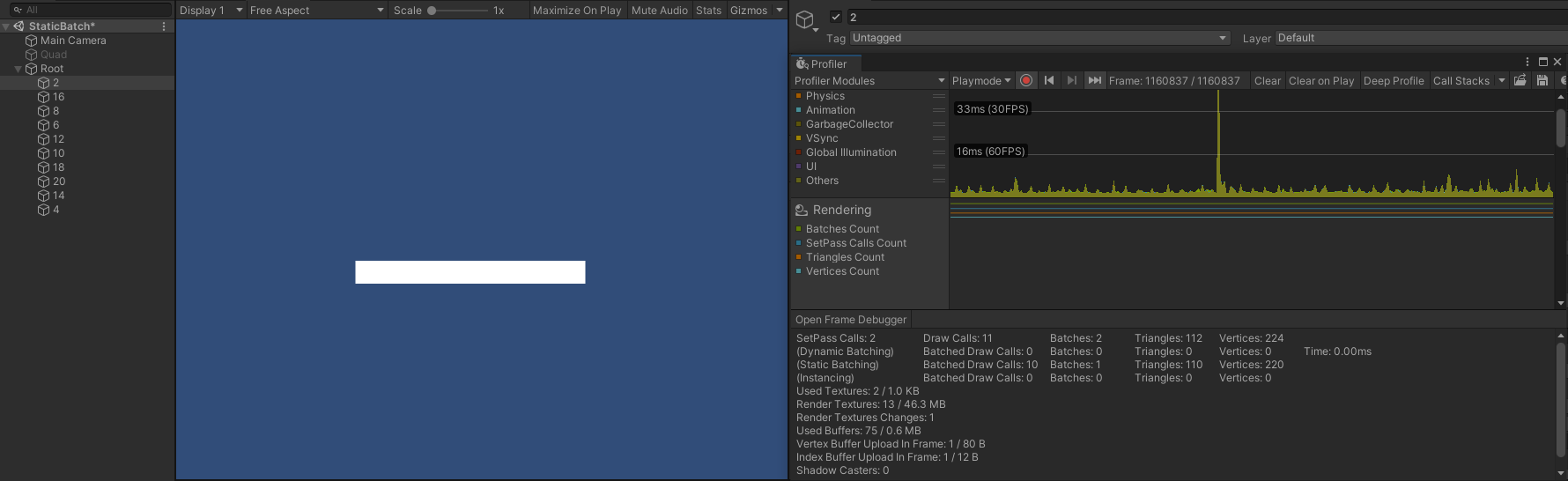
- 可以看到,SetPass Call 、Batch 同样能进行合并,但此时 Draw Call 变成了 11 ,将 GameObject 倒序,即第一个 submesh 离相机最远,如图所示:
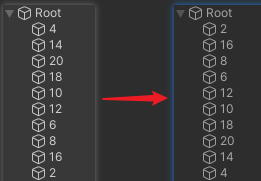
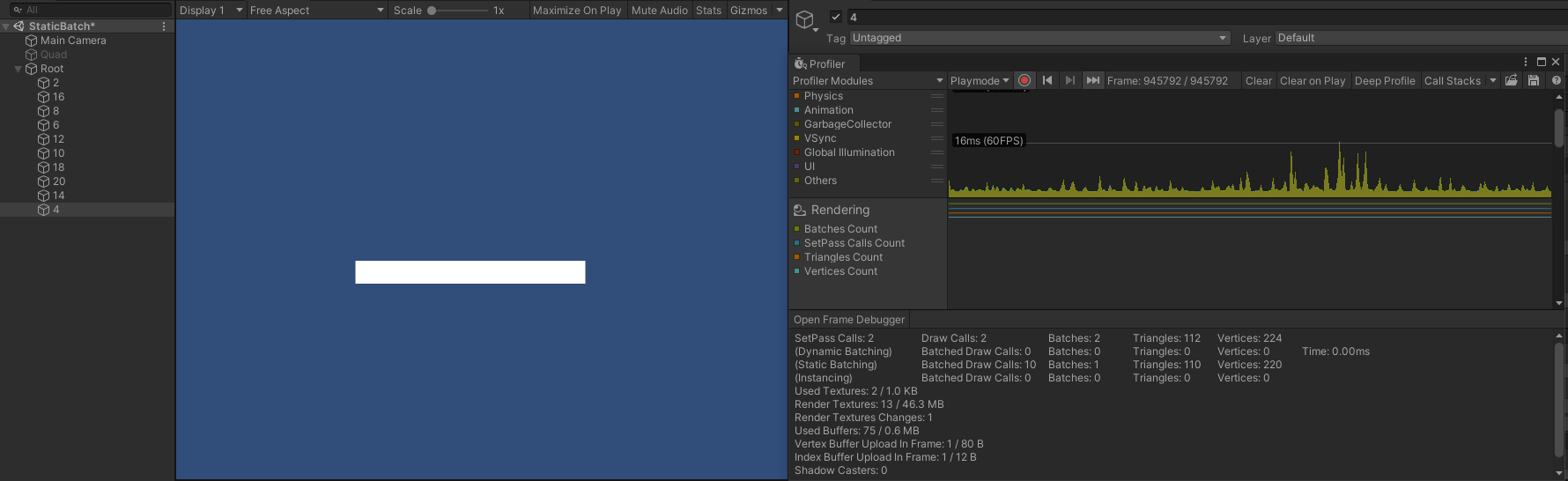
- 此时,Draw Call 又变回了 2 ,隐藏中间某些对象打断连续性的话,Draw Call 同样会发生变化,分成几段则需要几个 Draw Call 。
- 当交换第一、第二个对象(14 、4),Draw Call 变成了 4 ,此时渲染顺序为:
- 第二个对象(14)。
- 第一个对象(4)。
- 第三到第十个对象(20 、18 、10 、12 、6 、8 、16 、2)。
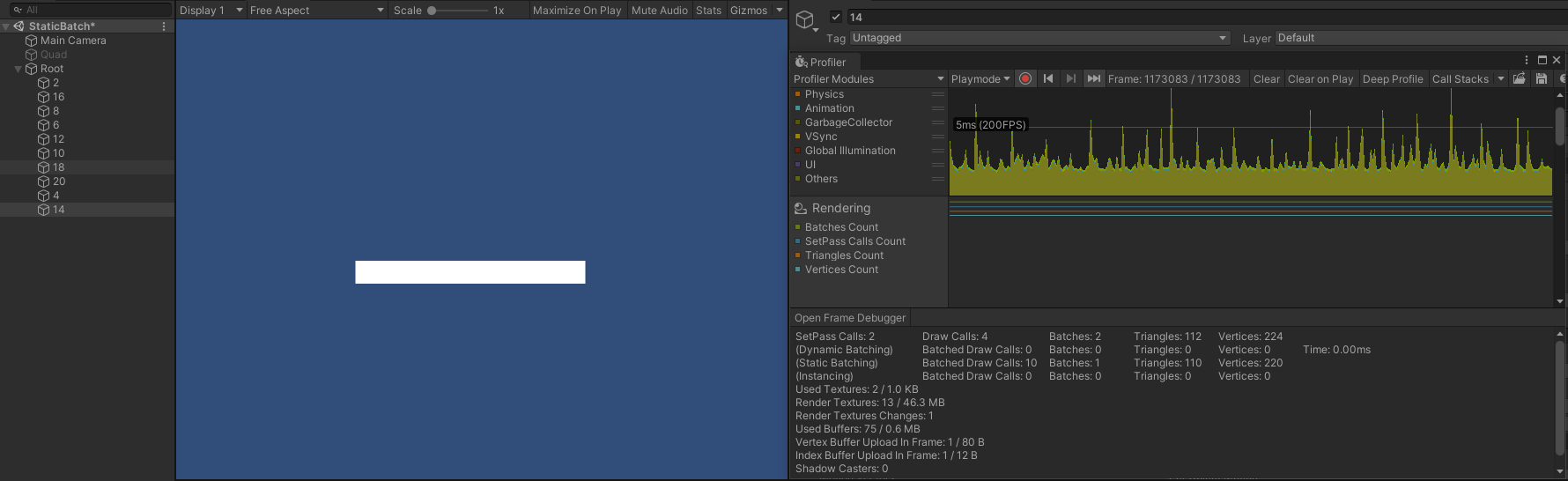
- 和不透明物体不同,半透明物体静态合批后,每个 submesh 仍然会按照从远到近的顺序进行渲染,此时如果渲染顺序和 submeshes 顺序不一致,即打断了 submeshes 的绘制顺序,则同样会使得 Draw Call 次数增加。
动态合批
- 官方文档说明如下:
- 动态合批通过在 CPU 上变换网格顶点,对共享相同配置的顶点进行分组,并在一次绘制调用中渲染它们。如果顶点存储相同数量和类型的属性,则它们共享相同的配置。
- 网格的动态合批通过将所有顶点转换为世界空间来工作。这个过程是在 CPU 上,而不是在 GPU 上。这意味着,只有当转换工作比绘制调用占用的资源更少,动态合批才能产生优化。在游戏机或 Apple Metal 等现代 API 上,绘制调用开销通常要低得多,此时动态合批通常不会带来性能提升。
- 动态合批的对象需要满足以下条件:
- 单个网格顶点数不超过 300 ,顶点属性不超过 900 。
- Transform 不能上设置为镜像,如一个对象的缩放为 1 ,另一个为 -1 。
- 需要使用相同的材质示例(shadow caster 渲染例外,只要 Unity 阴影通道所需的材质值相同即可)。
- 使用光照贴图时,光照贴图要相同。
- 前向渲染的多 Pass 渲染时,只能批处理首个 Pass ,不支持旧版延迟渲染。
- 对于动态生成几何体的组件,通常通过动态合批进行优化,如:
- 内置的 Particle Systems
- Line Renderers
- Trail Renderers
- 动态生成的几何体和网格的处理方式不同,主要方式为:
- 对于每个渲染器,Unity 将所有可以动态合批的内容构建到一个大的顶点缓冲区中。
- 渲染器为每个批次设置材质状态。
- Unity 将顶点缓冲区绑定到 GPU 。
- 对于批次中的每个渲染器,Unity 都会更新顶点缓冲区中的偏移量并提交新的绘制调用。
- 此外,对于动态合批,合并后的网格顶点索引数组的长度不能超过 32000 ,超过部分则会创建一个新的批次。
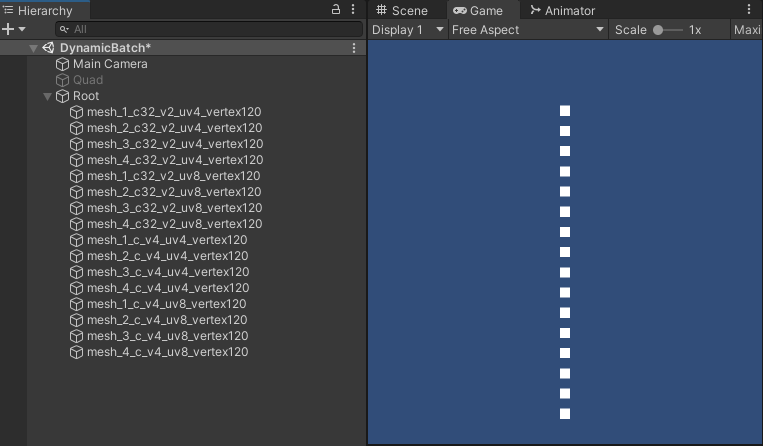
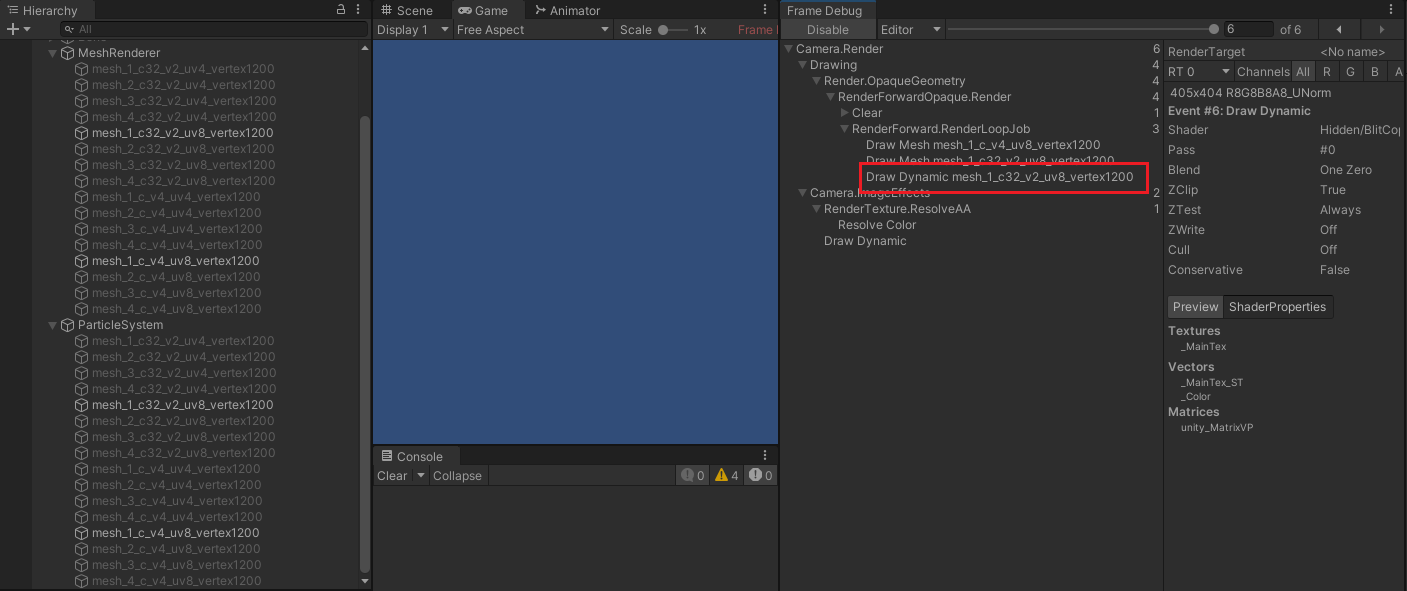
- 如上图所示,各个 GameObject 的名字含义如下:
- c32 :网格的每个顶点的 Color 为 4 bytes 。
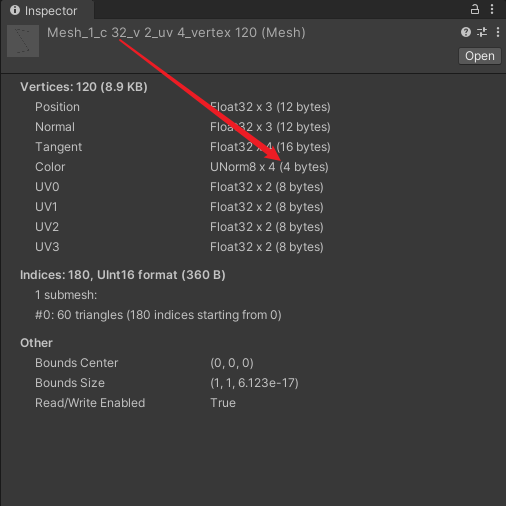
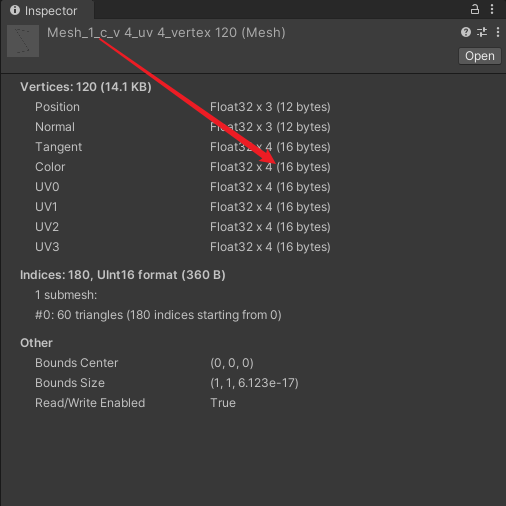
- c :网格的每个顶点的 Color 为 16 bytes 。
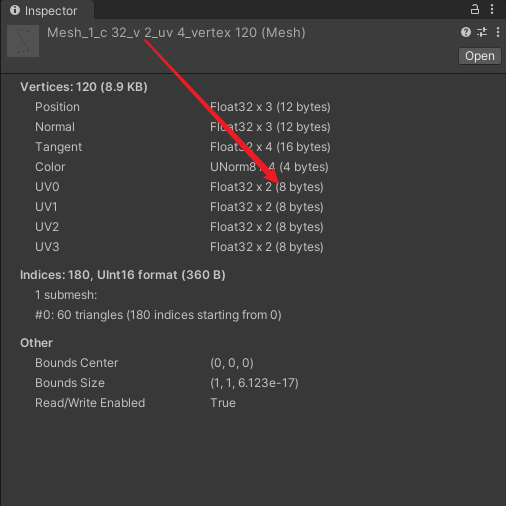
- v2 :网格的每个顶点的 uv 为 8 bytes 。
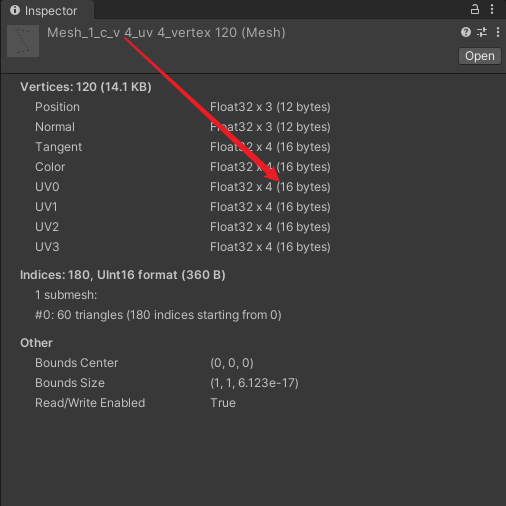
- v4 :网格的每个顶点的 uv 为 16 bytes 。
- uv1 :网格的每个顶点的 uv 数组,只有 uv0 有数据。
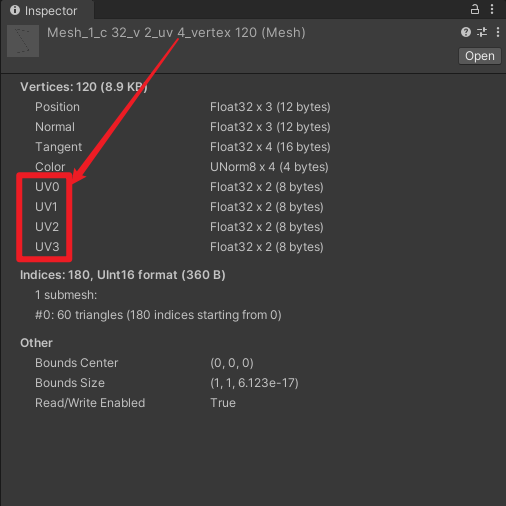
- uv8 :网格的每个顶点的 uv 数组,uv0 ~ uv7 都有数据。
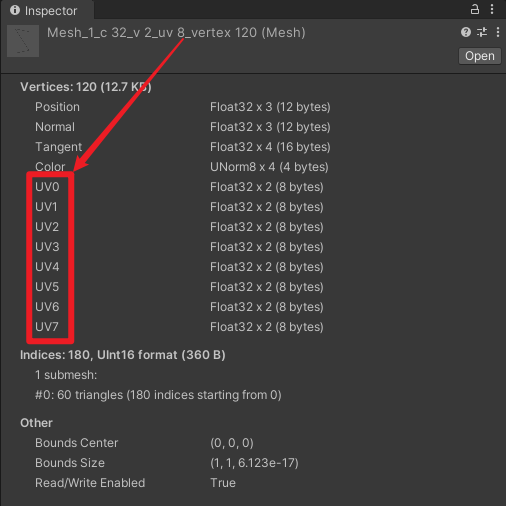
- vertex120 :网格的顶点数为 120。
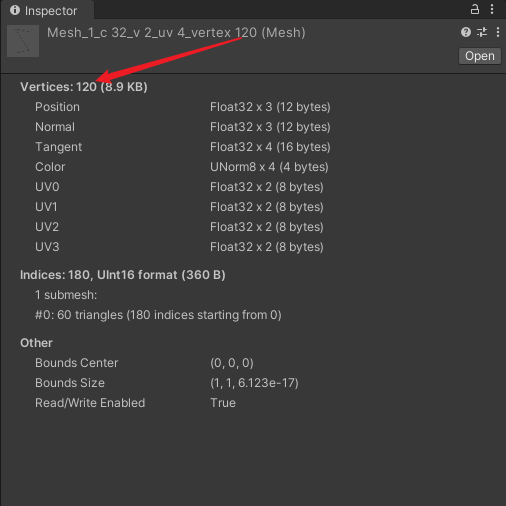
- c32 :网格的每个顶点的 Color 为 4 bytes 。
- 通过上面生成的网格对象,后续将分几个模块对动态合批进行分析。
数量限制
- 顶点属性包括位置、法线、切线、颜色、uv,然而动态合批计算的顶点属性数量,并不是传入顶点着色器的数据结构的数量,而是传入片元着色器的参数所引用到的顶点属性数据。
- 当 shader 使用位置、法线、切线、颜色、uv0 ~ uv3 时,shader 示例如下:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(v.vertex);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
s *= step(v.uv3.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
- 此时每个网格的顶点属性数量为 120 * 8 = 960 > 900 ,则所有网格都不能合批,如图所示:
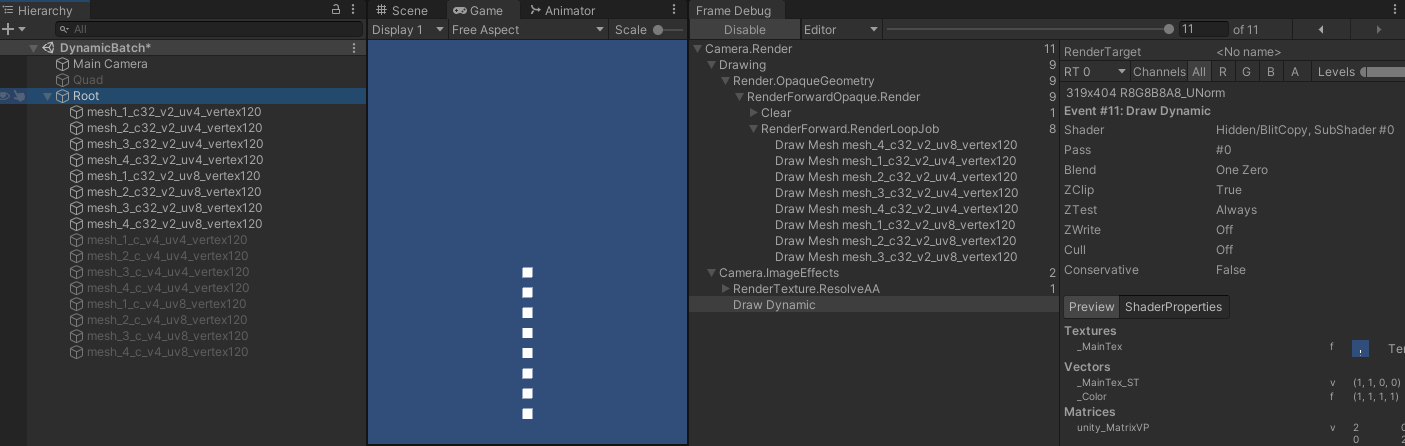
- shader 编译后的部分内容如下:
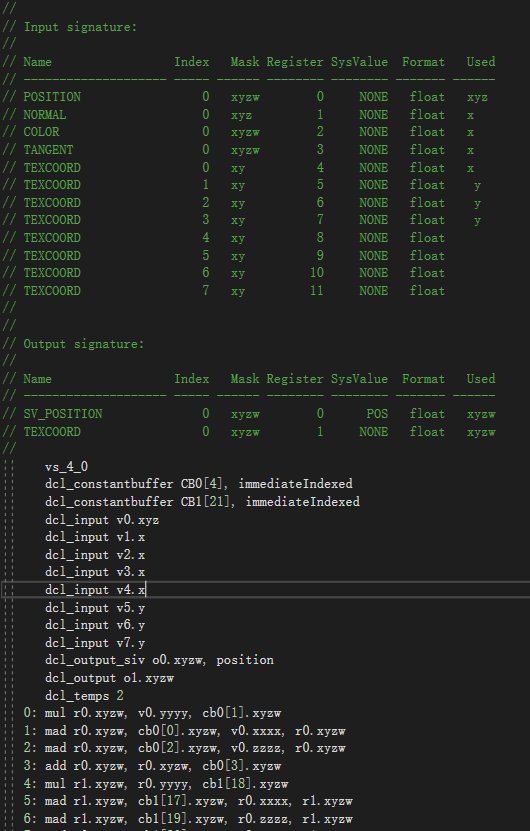
- 其中,v0 为 position ,v1 为 normal ,v2 为 color ,v3 为 tangent ,v4 ~ v7 为 uv0 ~ uv3 。
- 如果片元着色器没有引用顶点属性,即:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(v.vertex);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
s *= step(v.uv3.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
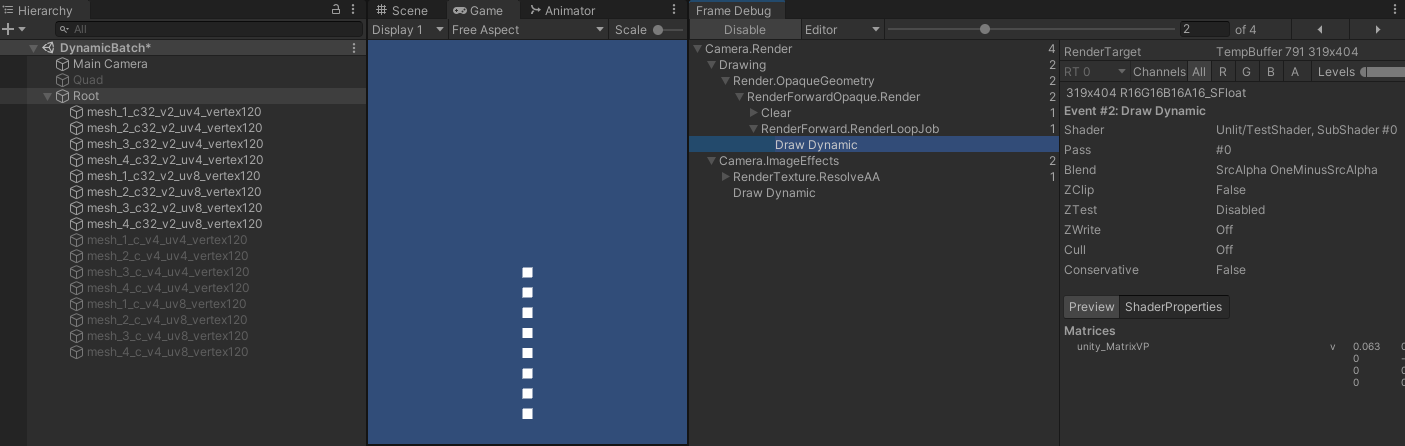
- 可以看到,此时原本不能合并的网格都合并了,也就是说,需要 shader 中真正引用的顶点属性只有位置,编译后的 shader 如下:
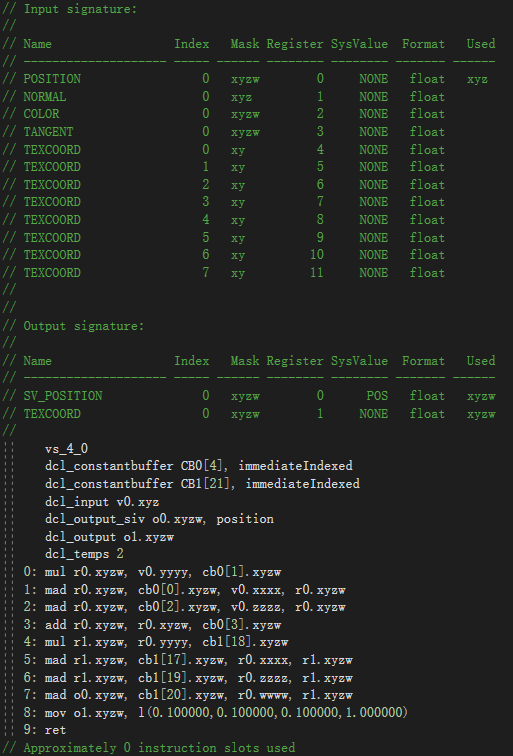
- 原本引用的有 v0 ~ v7 ,现在只剩 v0 ,也就是说,尽管在顶点着色器中有引用进行计算,但最终结果没有受到这些属性的值的影响,代表没有真正引用,所以编译后的 shader 中也不存在。
- 当 shader 使用位置、法线、切线、颜色、uv0 ~ uv2 时,即:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(v.vertex);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
- 此时每个网格的顶点属性数量为 120 * 7 = 840 < 900 ,则所有网格都能合批,如图所示:
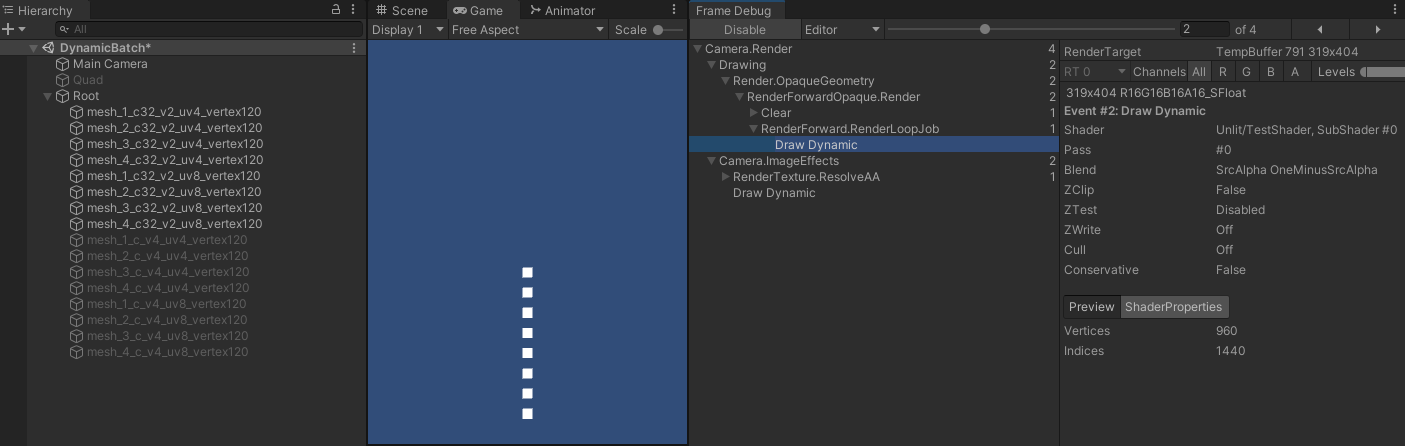
- 因此,动态合批的顶点属性数量限制,应该是 shader 真正引用的顶点属性的数量。
数据长度
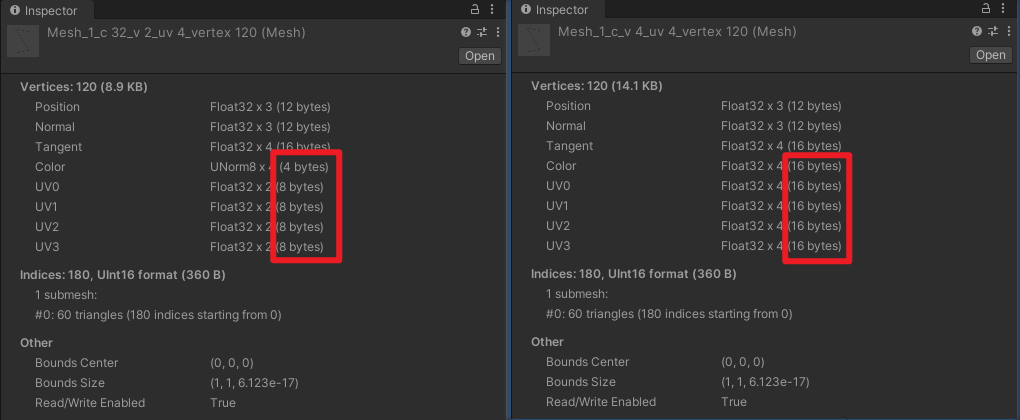
- 当 shader 使用位置、法线、切线、颜色,共计 4 个顶点属性时,每个网格的顶点属性数量为 120 * 4 = 480 < 900 ,应该所有网格都能合批,实际测试如图:
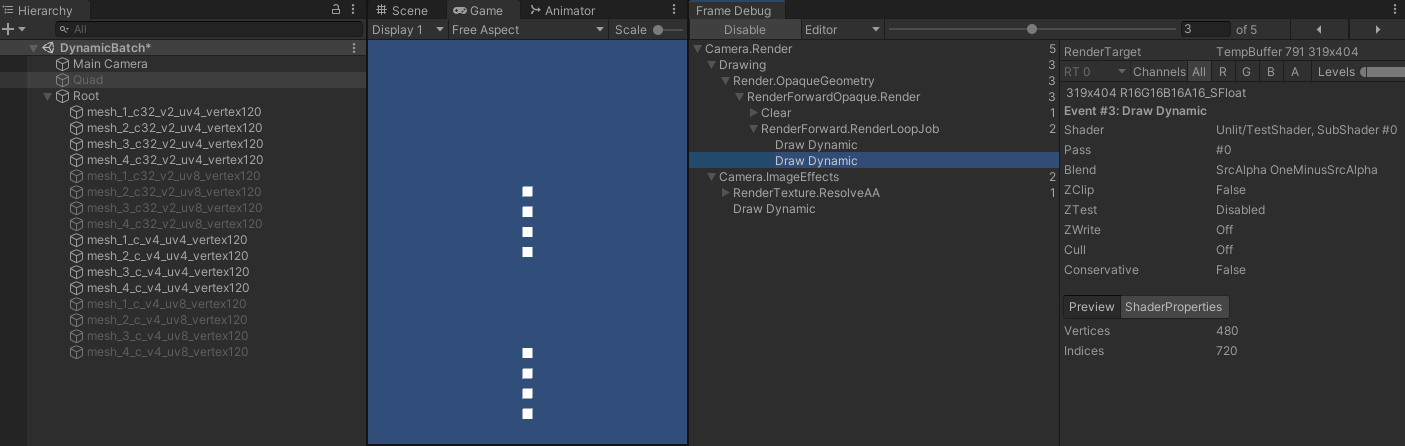
- 图中的对象分成了两个批次,一个批次的颜色为 4 bytes ,uv 为 8 bytes ,另一个批次的颜色为 16 bytes , uv 为 16 bytes 。
- 而当 shader 使用位置、法线、切线时,则所有网格又能正常合批:
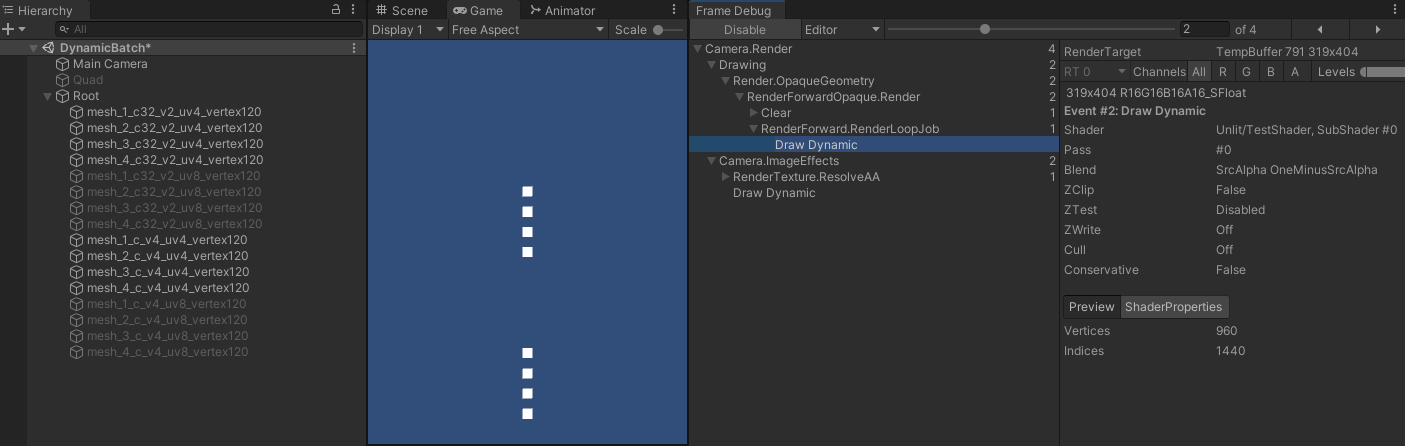
- 由于数据长度不一样的只有颜色和 uv ,所以当 shader 使用的所有顶点属性的数据长度都相同,就能合批,当使用了颜色属性后,由于颜色属性的数据长度不一样,则不能合批。
- 因此,shader 引用的网格顶点属性,数据长度相同的,才能进行动态合批。
位置信息
- 当 shader 不使用顶点属性时:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(float3(0, 0, 0));
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
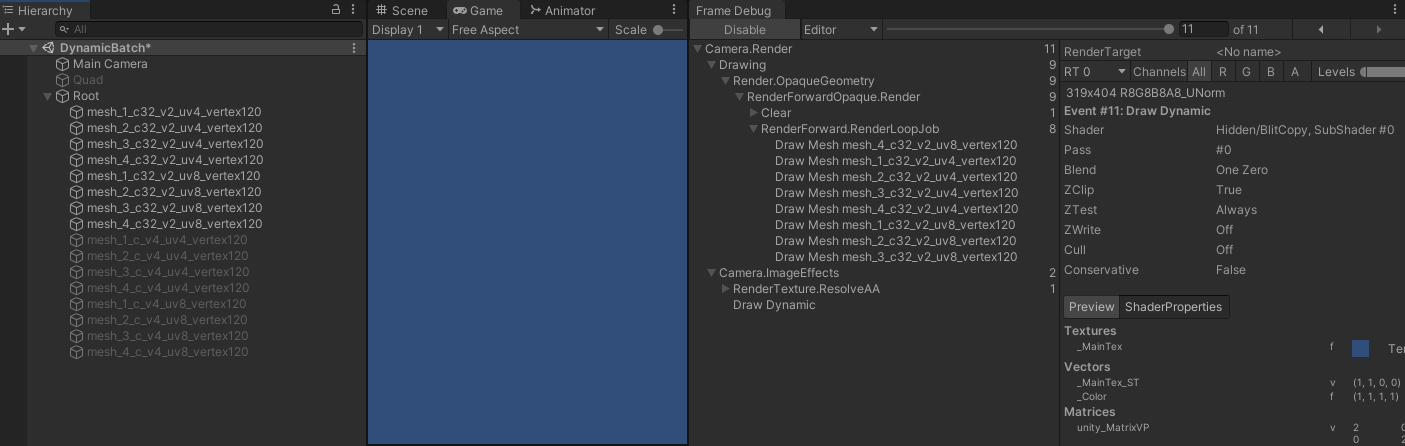
- 当 shader 只使用法线时:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(v.normal);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
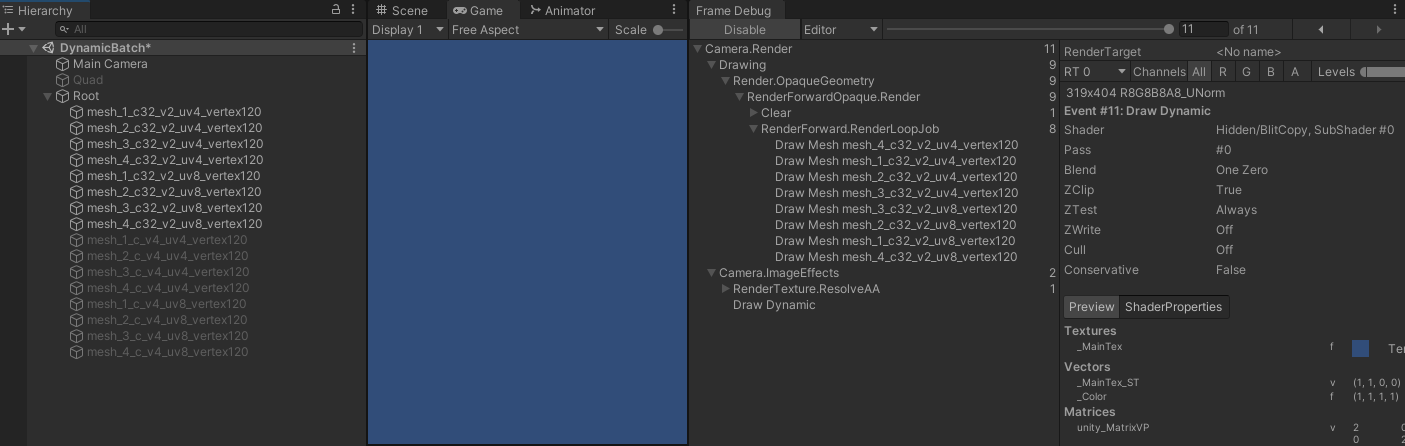
- 当 shader 只使用 uv0 时:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(float3(v.uv0.x, v.uv0.y, 0));
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
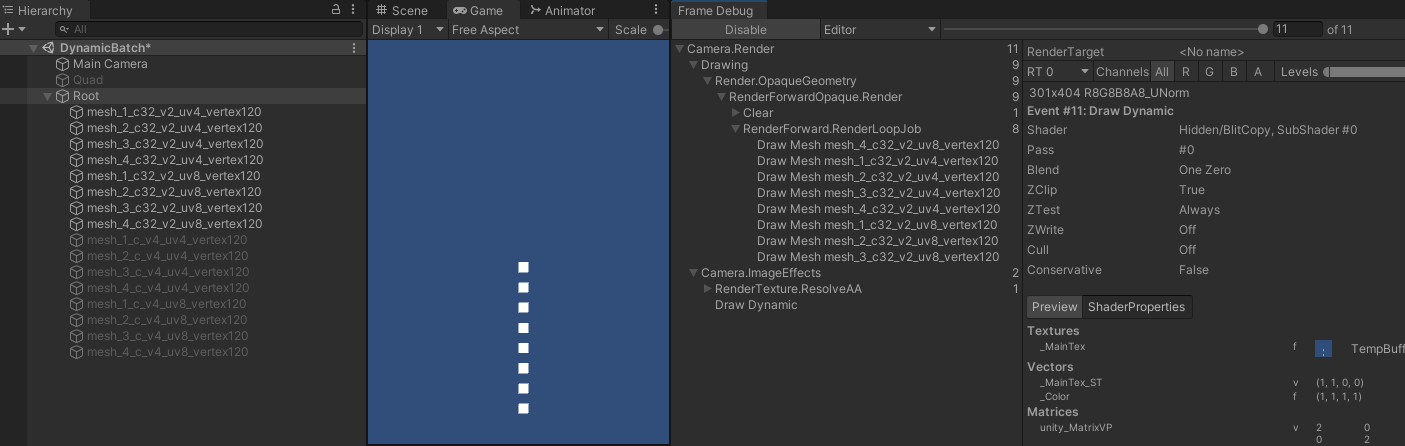
- 而当 shader 使用位置,但不用于顶点坐标计算时:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(float3(0, 0, 0));
s *= step(v.vertex.x, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
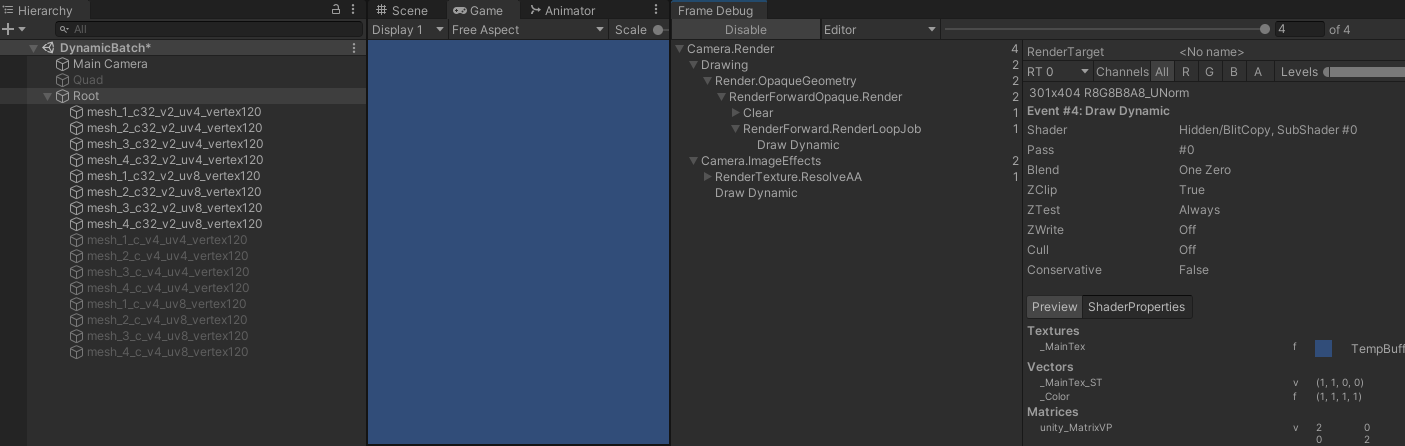
- 从上面所有测试可以看出,shader 只要没有引用位置信息,动态合批就都会失效,无论顶点属性数量有没有超出上限。只有引用了位置信息,动态合批才会开始生效,无论位置信息是不是用于最终的顶点位置计算。
蒙皮网格
- 蒙皮网格,即带有骨骼权重的网格,如图所示:
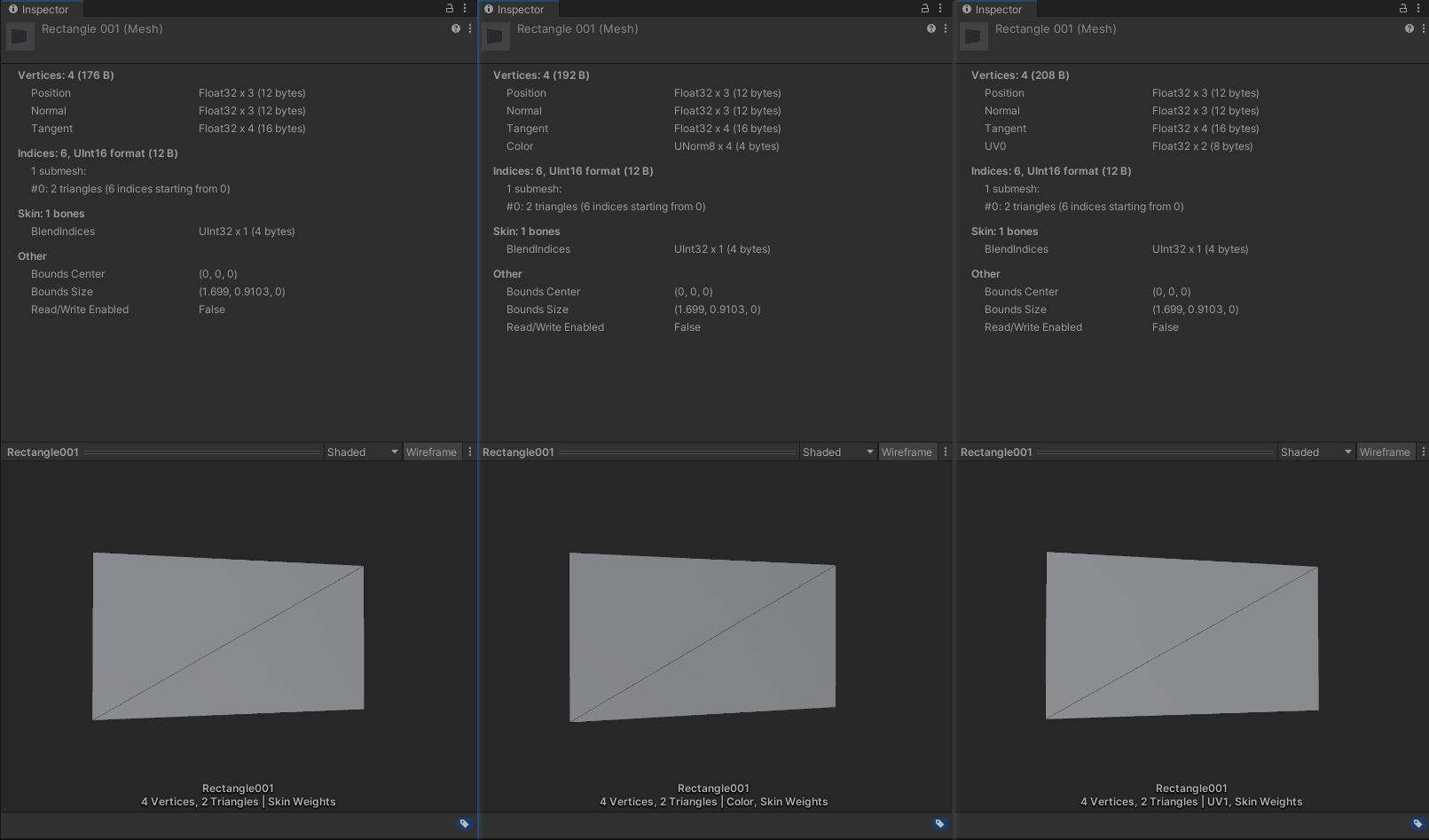
- 图中的网格为两个三角面,使用一根骨骼进行绑定。从左到右分别为顶点无颜色和 uv 、 顶点有颜色无 uv 、顶点无颜色有 uv 。合批情况如下:
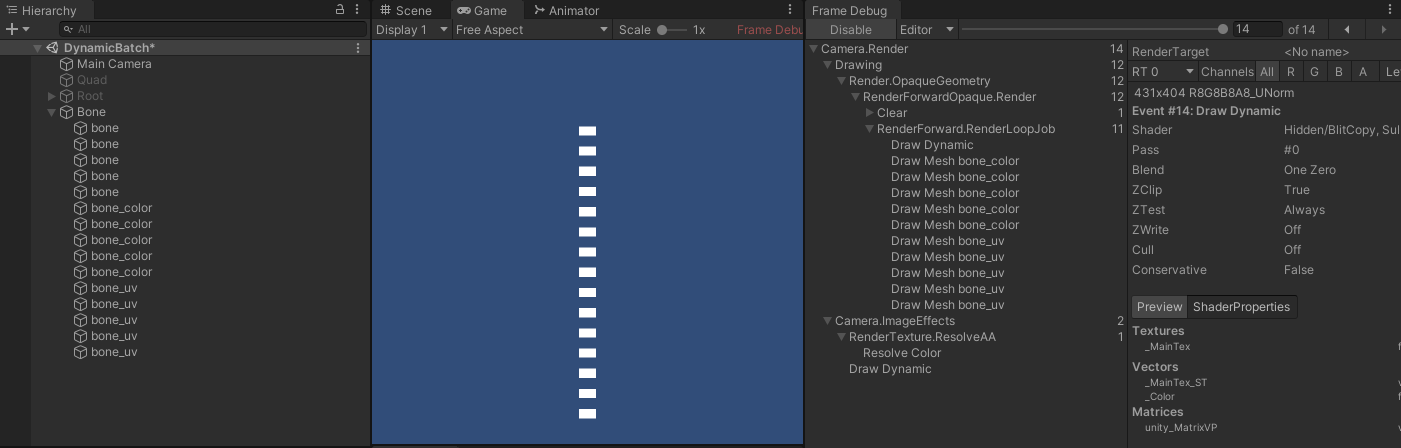
- 可以看到,没有顶点颜色和 uv 的网格,都能动态合批,而当存在顶点颜色或者 uv 时,则所有都不能合批。由于蒙皮网格通常会带有 uv 来采样纹理,因此通常蒙皮网格都不能合批。
粒子系统
- 粒子系统(ParticleSystem)默认使用动态合批处理,但粒子系统的合批规则和常规的动态合批规则又有些差别。
数据长度、数量、位置信息
- 当网格属性有位置、法线、切线、颜色、uv0 ~ uv7 ,shader 使用所有数据时,即:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = UnityObjectToClipPos(float3(0, 0, 0));
s *= step(v.vertex.x, 0);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
s *= step(v.uv3.y, 0);
s *= step(v.uv4.y, 0);
s *= step(v.uv5.y, 0);
s *= step(v.uv6.y, 0);
s *= step(v.uv7.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
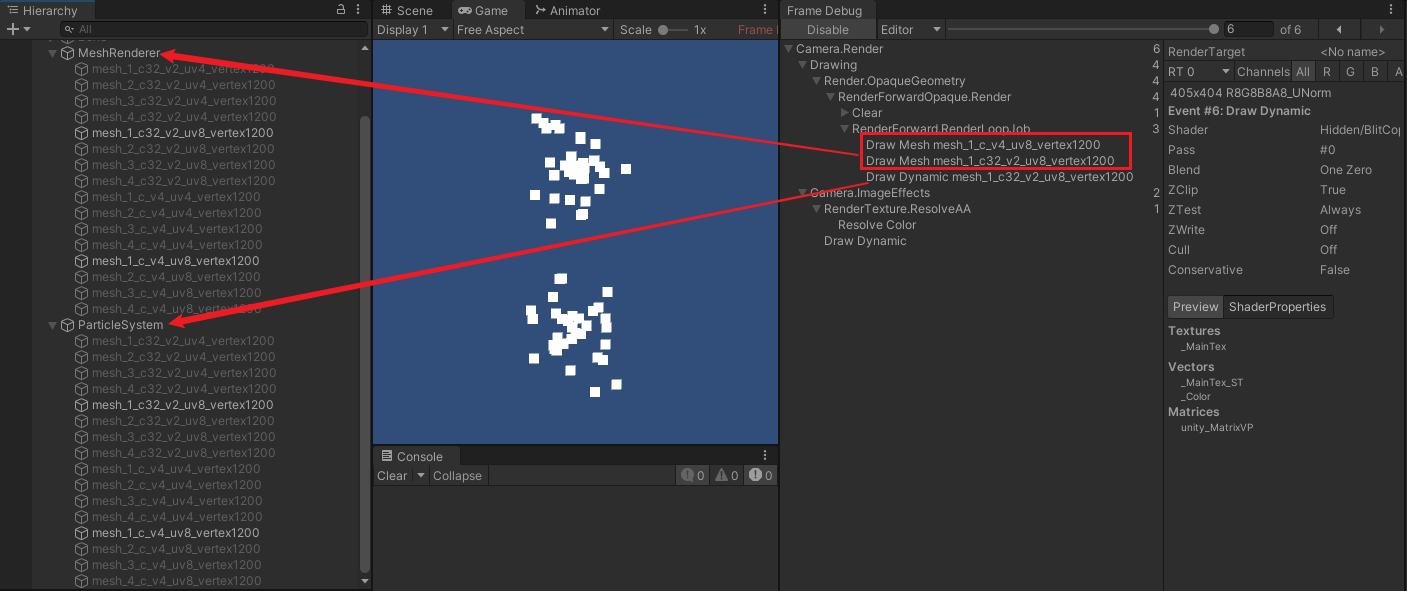
- 其中,MeshRenderer 无法进行动态合批,因为顶点数量、顶点属性数量、数据长度等都不符合动态合批要求。然而相同网格和材质球下,粒子特效却能正常合批。
- 当 shader 不使用位置时,即:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = float4(0, 0, 0, 0);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
s *= step(v.uv3.y, 0);
s *= step(v.uv4.y, 0);
s *= step(v.uv5.y, 0);
s *= step(v.uv6.y, 0);
s *= step(v.uv7.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
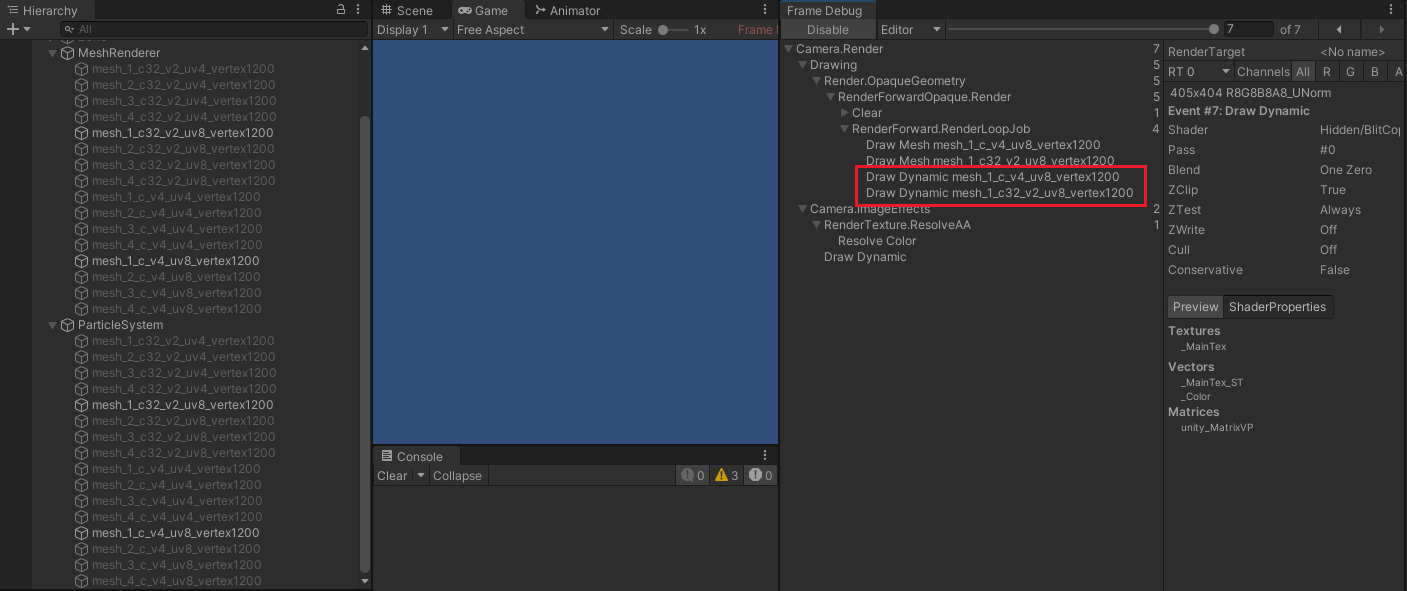
- 此时,粒子特效则不能正常进行动态合批。
- 而当 shader 使用位置,但不用于顶点坐标计算时:
...
v2f vert (appdata v)
{
v2f o;
float s = 1;
o.vertex = float4(0, 0, 0, 0);
s *= step(v.vertex.x, 0);
s *= step(v.normal.x, 0);
s *= step(v.tangent.x, 0);
s *= step(v.color.x, 0);
s *= step(v.uv0.x, 0);
s *= step(v.uv1.y, 0);
s *= step(v.uv2.y, 0);
s *= step(v.uv3.y, 0);
s *= step(v.uv4.y, 0);
s *= step(v.uv5.y, 0);
s *= step(v.uv6.y, 0);
s *= step(v.uv7.y, 0);
o.color = float4(0.1, 0.1, 0.1, 1) * s;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = fixed4(1,1,1,1);
return col;
}
...
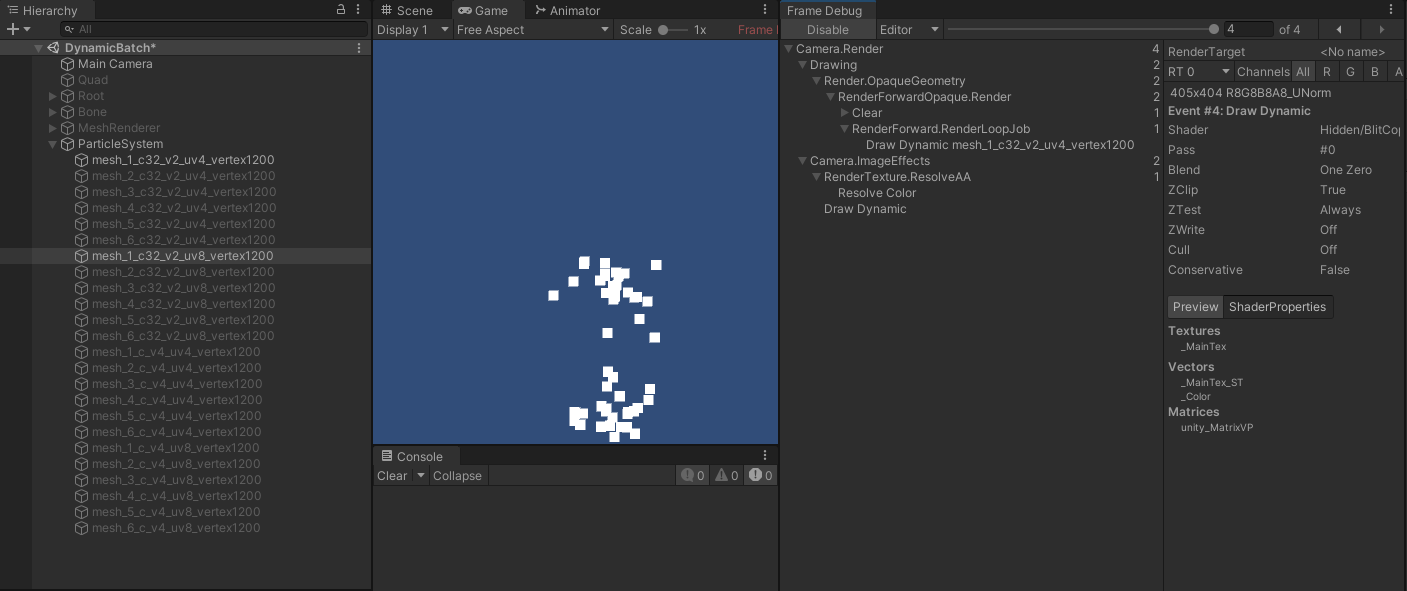
- 同样,粒子特效又恢复正常动态合批。
- 也就是说,粒子特效在动态合批过程中,不会受到顶点数量、顶点属性数量、数据长度的限制,但仍需要使用顶点位置信息,才能正常合批。
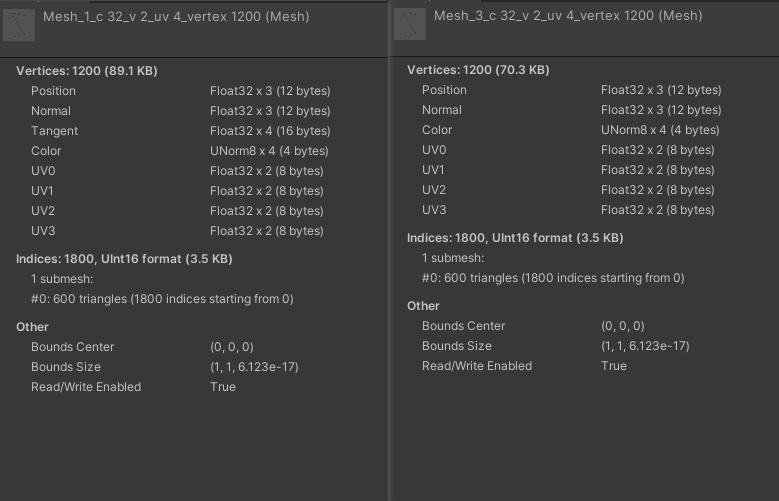
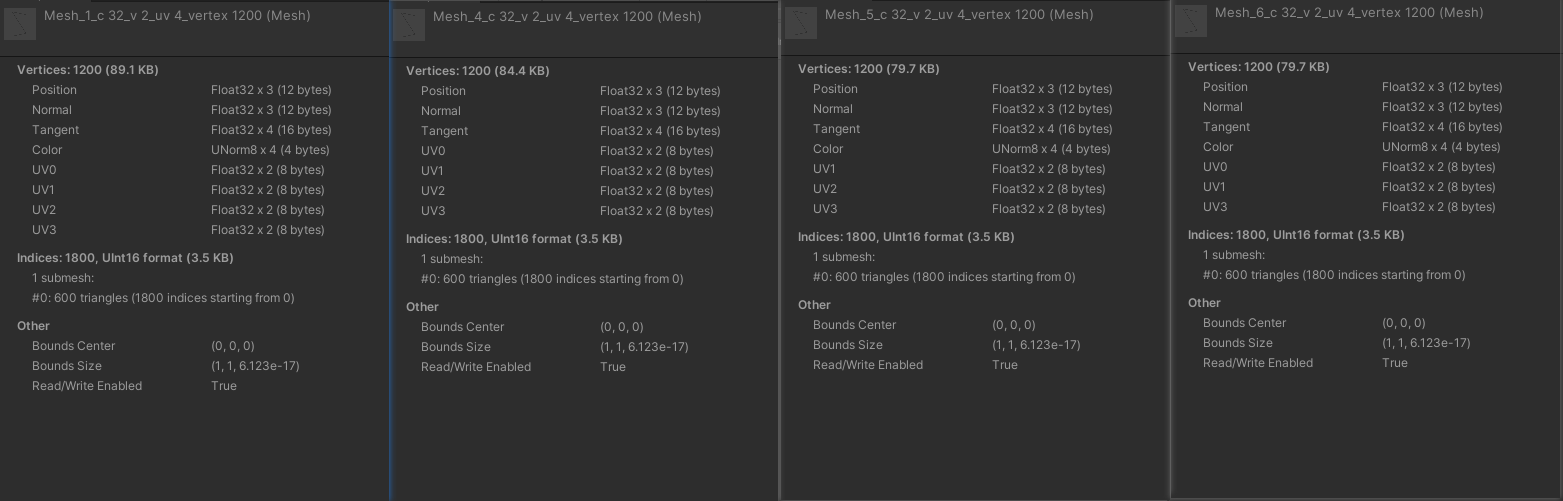
网格顶点属性
- 当两个网格的顶点属性分别为:
- 位置、法线、切线、颜色、uv0 ~ uv3
- 位置、法线、切线、颜色、uv0 ~ uv7
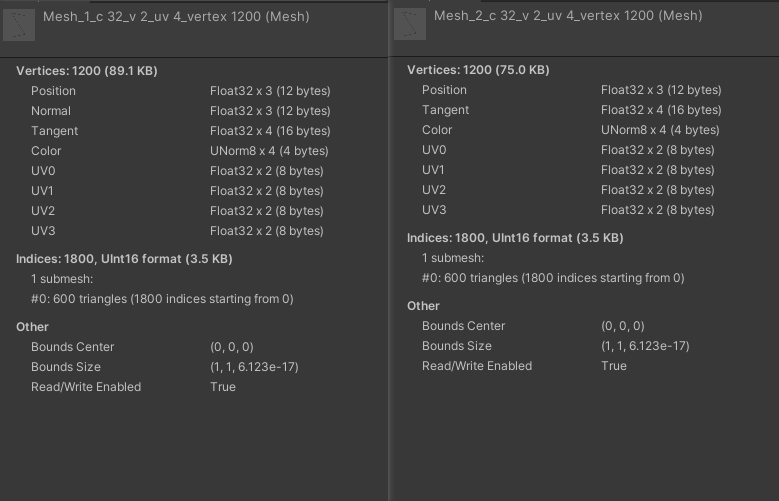
网格顶点属性相差 uv4 ~ uv7,正常合批
- 当两个网格的顶点属性分别为:
- 位置、法线、切线、颜色、uv0 ~ uv3
- 位置、切线、颜色、uv0 ~ uv3
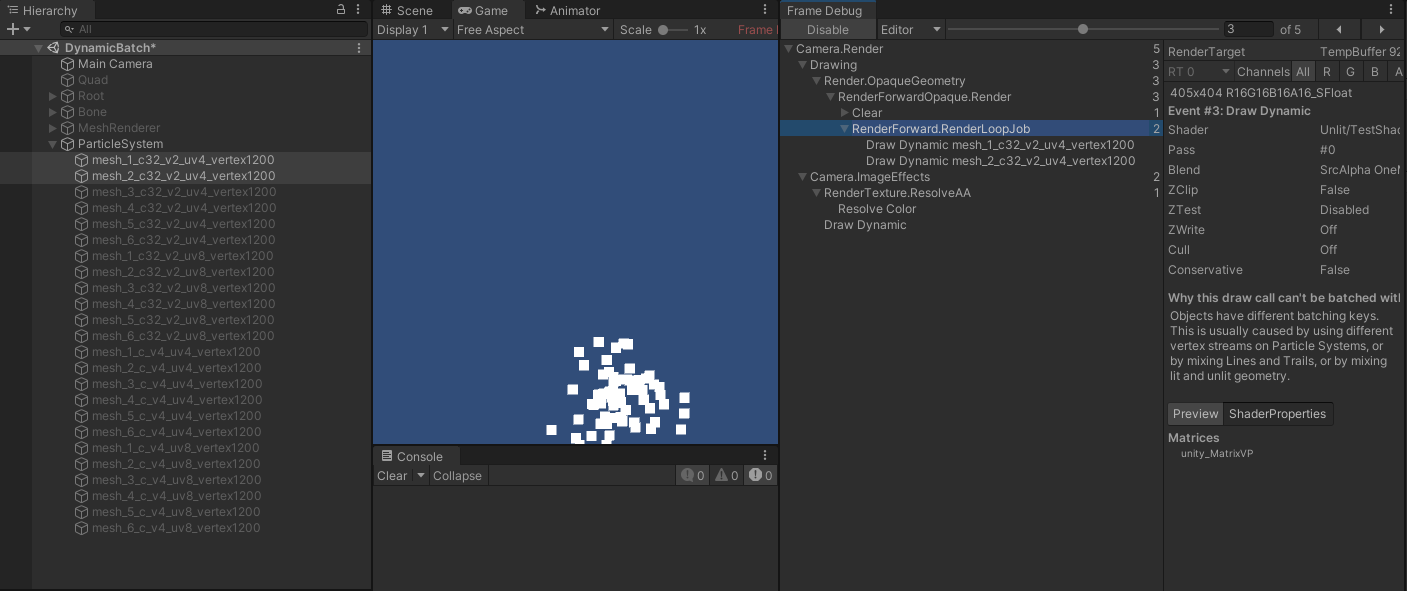
网格顶点属性相差法线,不能合批
- 当两个网格的顶点属性分别为:
- 位置、法线、切线、颜色、uv0 ~ uv3
- 位置、法线、颜色、uv0 ~ uv3
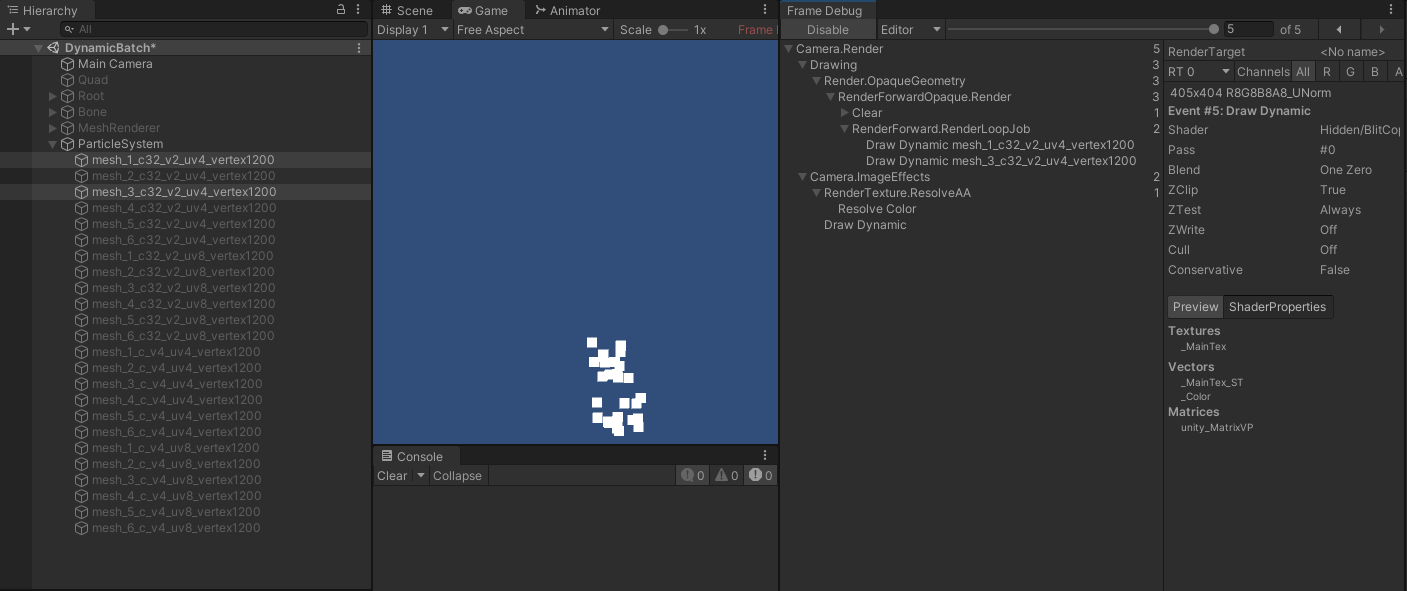
网格顶点属性相差切线,不能合批
- 当两个网格的顶点属性分别为:
- 位置、法线、切线、颜色、uv0 ~ uv3
- 位置、法线、切线、uv0 ~ uv3 / 位置、法线、切线、颜色、uv1 ~ uv3 / 位置、法线、切线、颜色、uv0 、uv1 、uv3
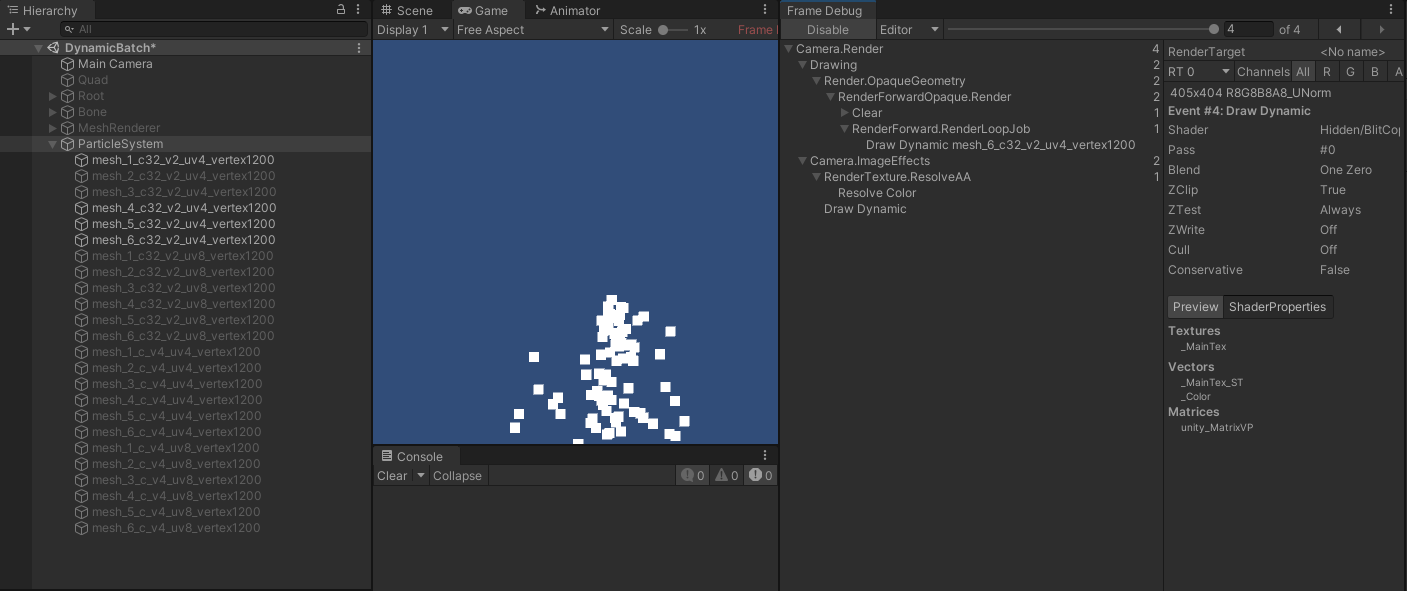
网格顶点属性相差颜色/uv1/uv3,正常合批
- 调整渲染顺序后,将所有粒子特效进行绘制,合并成三个批次。
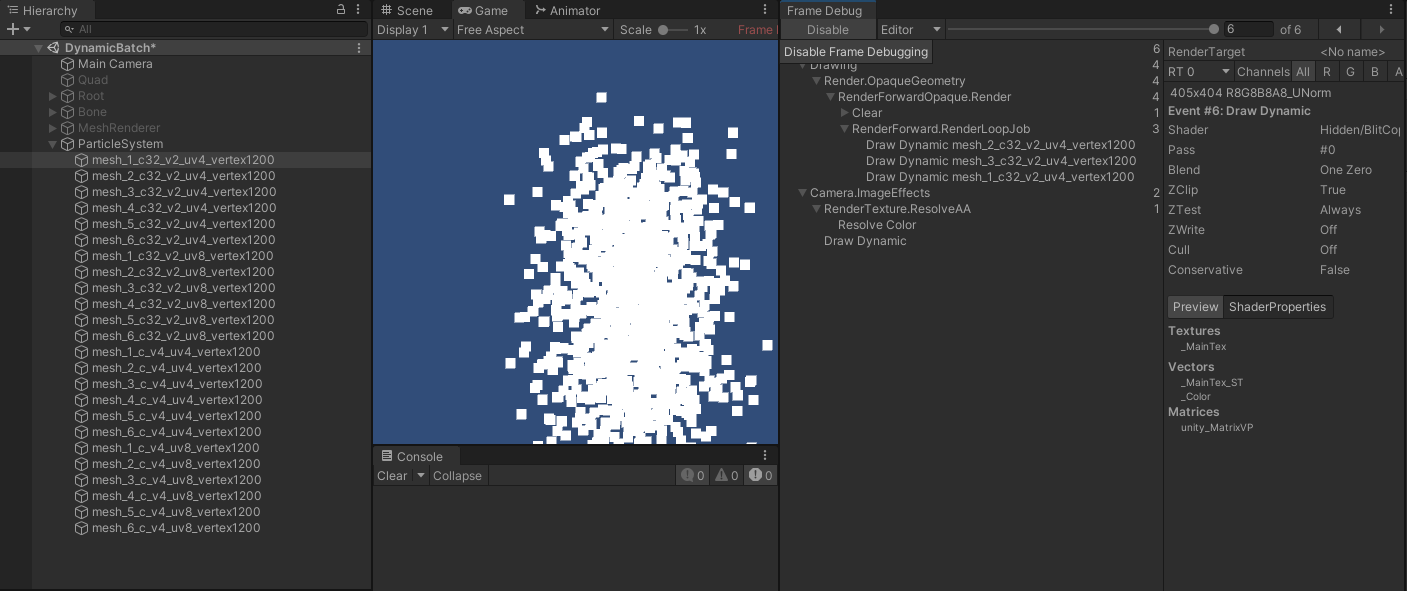
- 从以上数据可以看出,粒子特效动态合批会受到网格的顶点属性影响,其中,对于具有基本属性(位置、法线、切线)任意组合的网格,相同组合的网格(含蒙皮网格)才能动态合批,而颜色和 uv 不影响动态合批结果。
网格数量
- 多个具有相同材质的粒子特效,当设置了多个网格时,能否合批取决于首个不为空的网格。当首个不为空的网格具有相同基本属性组合,则所有粒子特效都能正常合批,即使后续网格不具备相同基本属性组合。
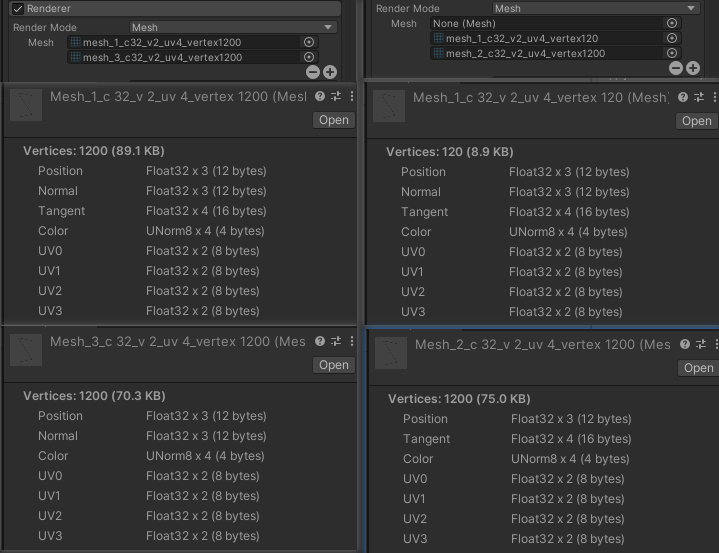
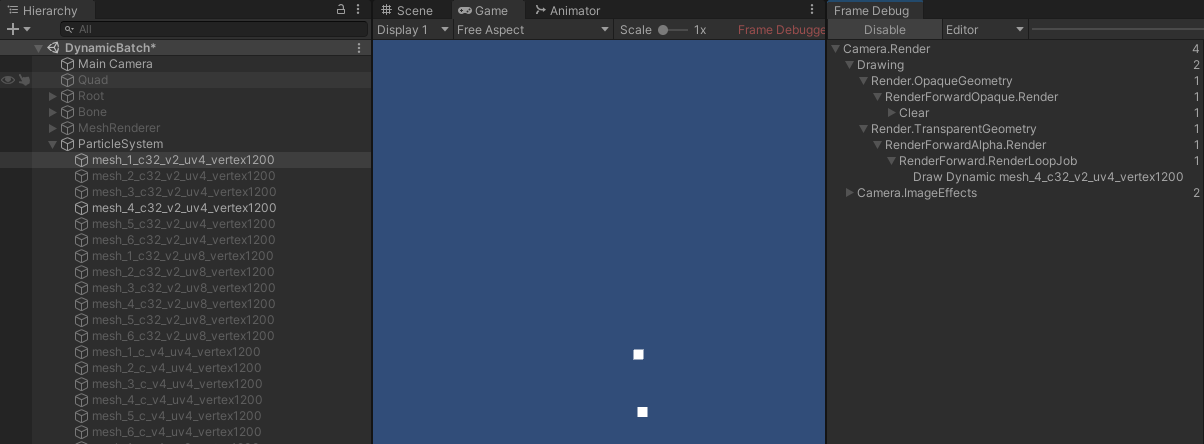
- 可以看到,首个不为空的网格具有相同基本属性组合,而第二个不为空的网格则组合不一致,但最终都能正常合批。
- 当调换第二个对象的网格顺序时:

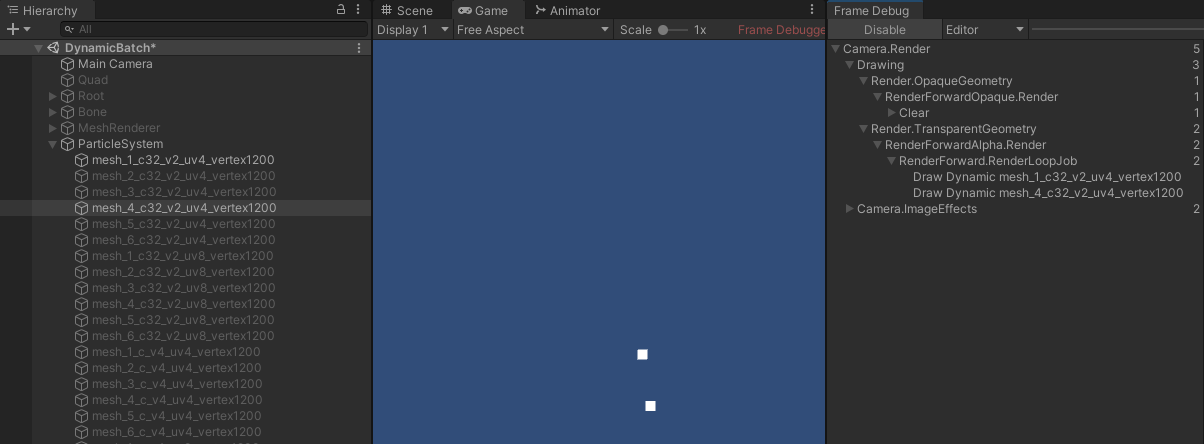
- 调换后,首个不为空的网格基本属性组合不一致,因此变成了两个批次。
- 多网格的粒子特效,每次都会从网格列表中取其中一个网格来发射粒子,数量受到 Max Particles 和 Emission 下的参数限制。
渲染模式
- Renderer 下的 Render Mode ,Mesh 模式和其他模式相互不能合批,如:
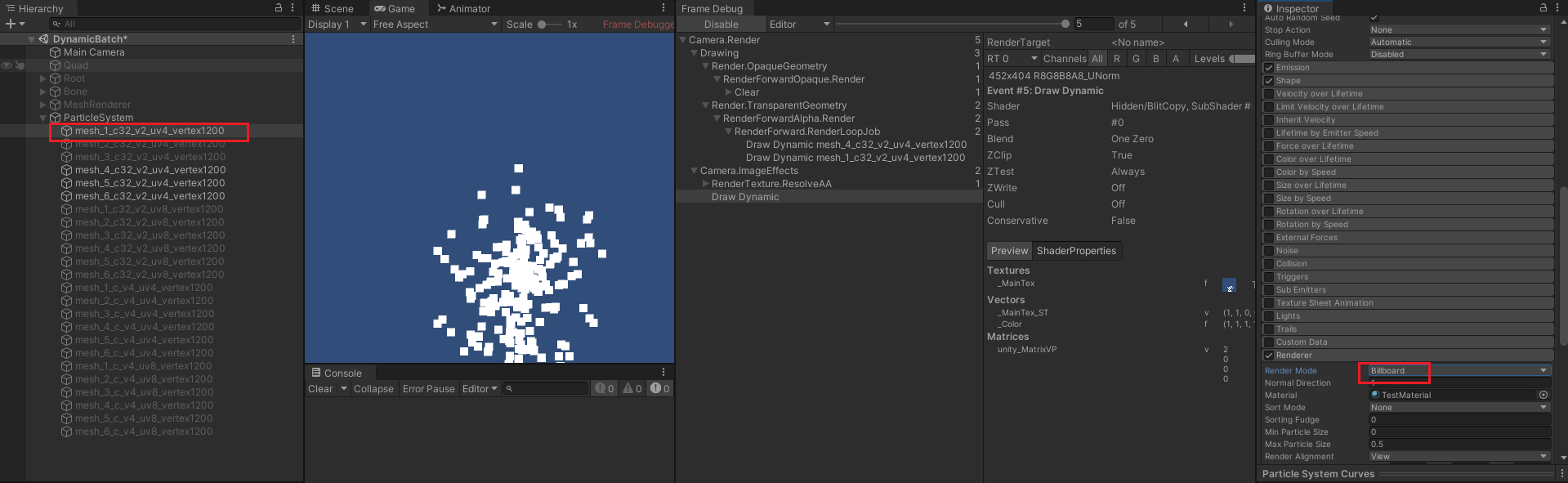
- 原本 4 个粒子特效都能正常合批,当第一个粒子特效改为 Billboard 模式后,则不能和其他 3 个 Mesh 模式的特效合批。
- 所有 Billboard 模式,都会创建一个 4 顶点 2 三角面的网格进行渲染。
材质球数量
- 当使用 Trails 效果时,Renderer 下会增加多一个 Trail Material 项,用于渲染拖尾效果。而拖尾效果无法和基础特效进行合批,即使材质球相同。
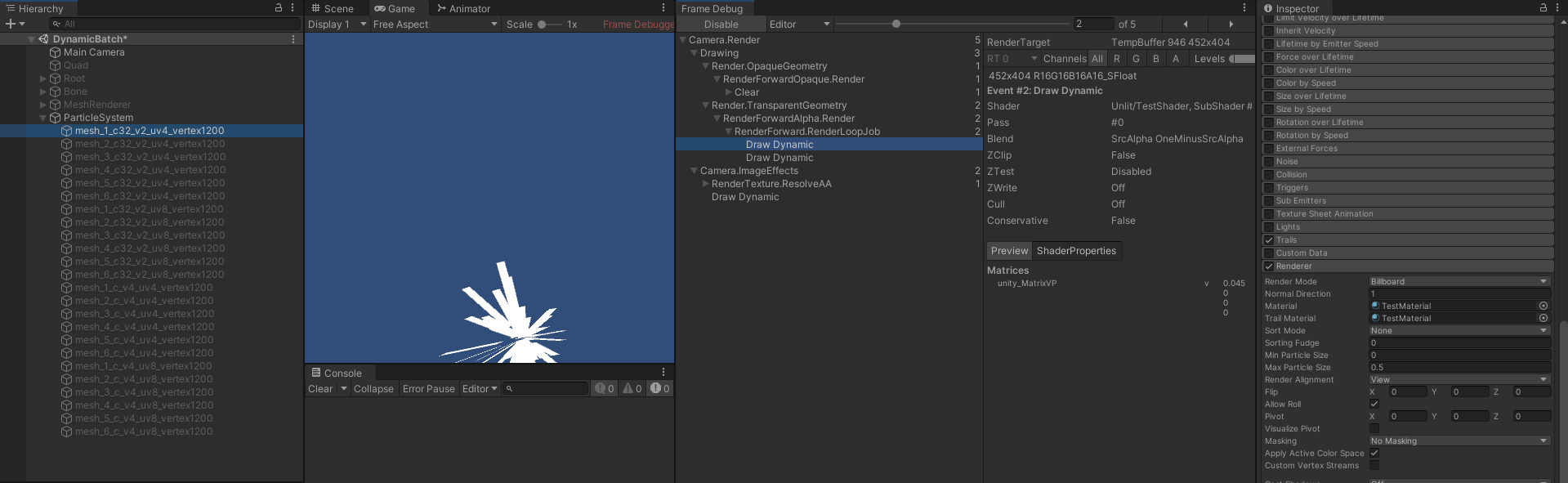
- 多个使用 Trails 效果的特效,如果使用相同材质球,则主效果和拖尾效果能分别合批。
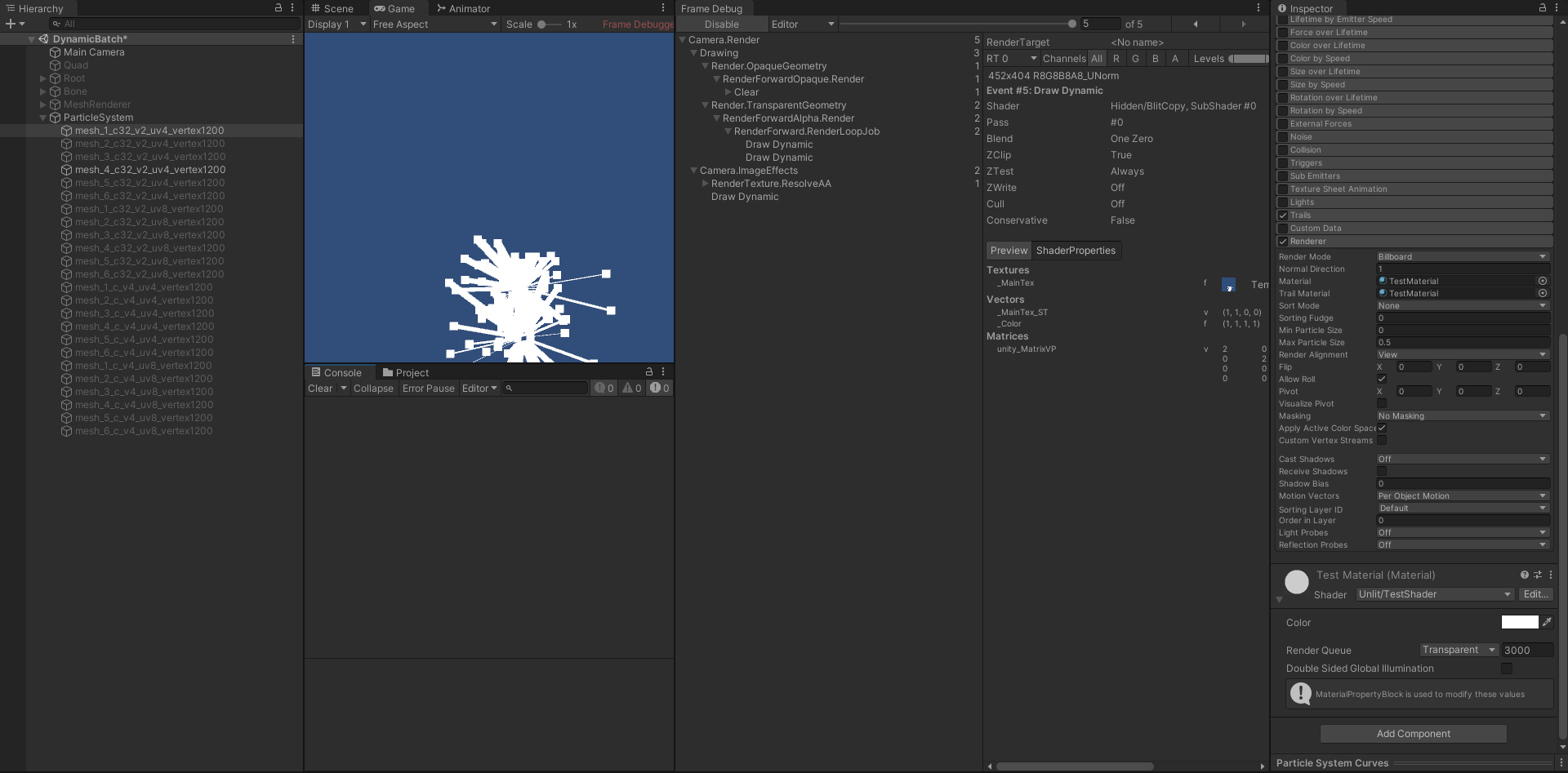
- 如果多个使用 Trails 效果的特效,Trails 效果使用和主效果不同的材质球,则会根据渲染队列顺序进行绘制。
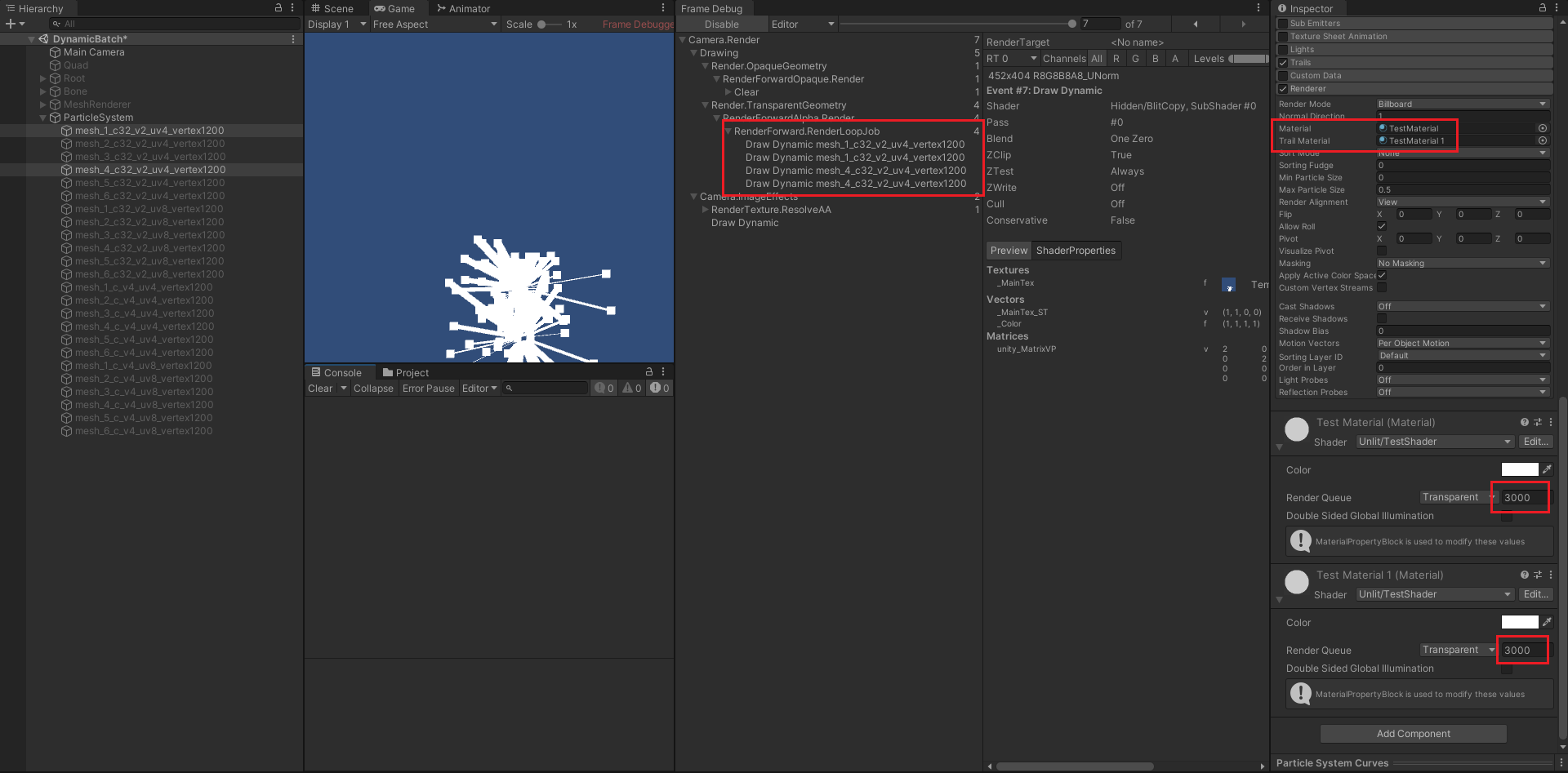
- 如上图所示,每个粒子特效上的两个材质球的渲染队列都为 3000,则会先渲染特效 1 ,再渲染特效 2 ,所以会产生 4 个批次。
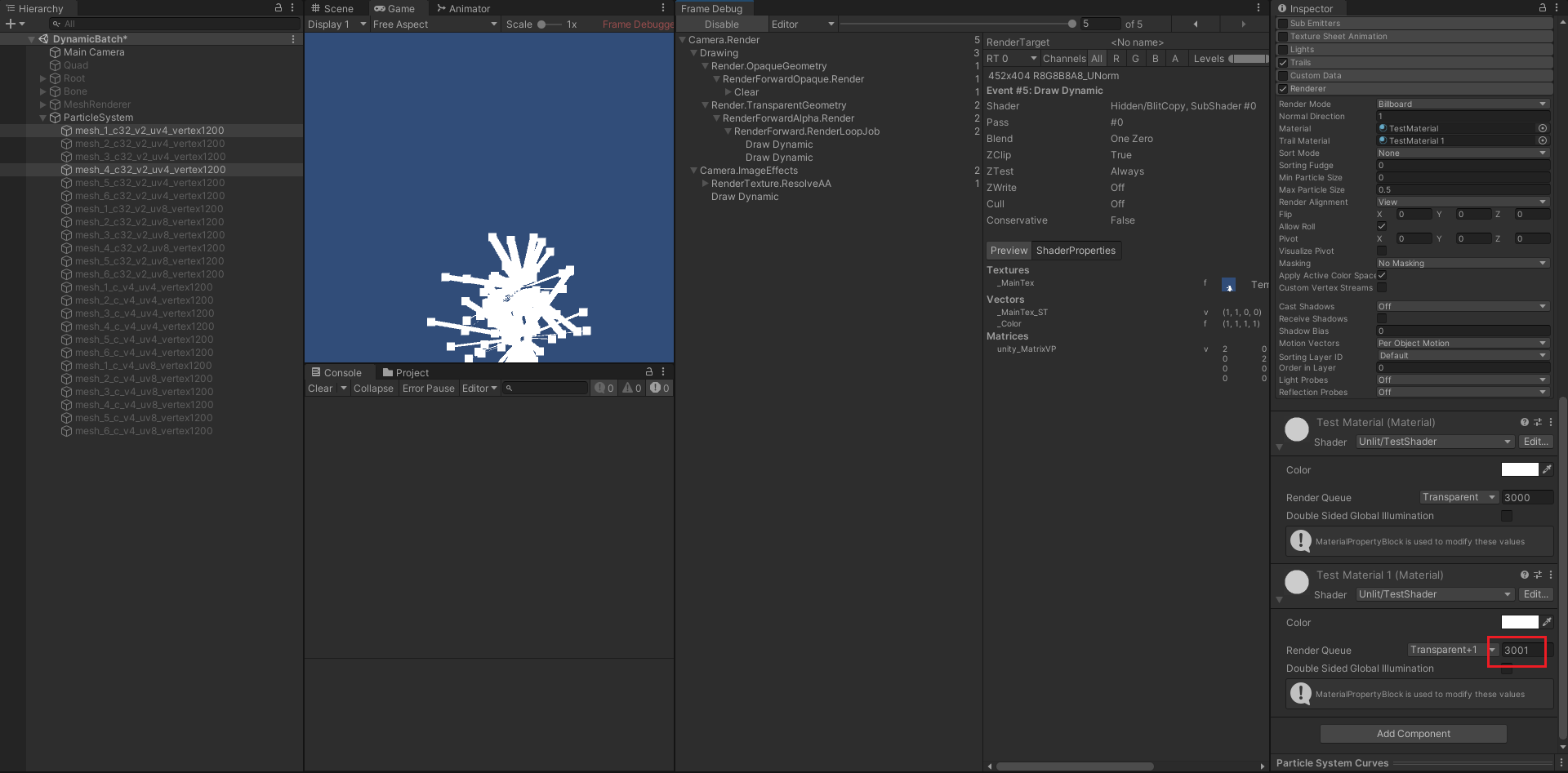
- 当调整拖尾特效的渲染队列为 3001 时,则拖尾特效统一渲染,最终能合并成 2 个批次。
GPU Instancing
- 官方文档说明如下:
- GPU Instancing 是一种绘制调用优化方法,可以渲染单个绘制调用中具有相同材质的相同网格副本,网格的每个副本称为一个实例。对于绘制单个场景中多次出现的网格时非常有效,例如树木或灌木丛。为了增加变化并减少重复,每个实例可以具有不同的属性,例如 Color 或 Scale 。
- 使用 GPU Instancing 的条件如下:
- shader 必须支持 GPU Instancing ,包括对应的 shader 代码支持以及开启 Enable GPU Instancing 选项。
- 网格需要使用 MeshRenderer 组件或者使用 Graphics.RenderMesh 方法调用。不支持 SkinnedMeshRender 组件,不支持使用 SRP Batcher 的 MeshRenderer 组件。
- Graphics.RenderMeshInstanced 或 Graphics.RenderMeshIndirect 方法的每次调用都是一个独立的 draw call ,相互不会合并。
- 顶点数量较少的网格无法使用 GPU 实例化进行高效处理,因为 GPU 无法以充分利用 GPU 资源的方式分配工作。这种处理效率低下会对性能产生不利影响,效率低下的阈值取决于 GPU,但一般来说,不要对顶点数量少于 256 个的网格使用 GPU 实例化。如果想多次渲染具有少量顶点的网格,最佳做法是创建一个包含所有网格信息的单个缓冲区,并使用它来绘制网格。
- shader 代码相关内容有:
| 内容 | 说明 |
|---|---|
| #pragma multi_compile_instancing | 生成实例变体。对于顶点和片元着色器是必须的,对于表面着色器是可选的。 |
| #pragma instancing_options | 指定 Unity 用于实例的选项。 |
| UNITY_VERTEX_INPUT_INSTANCE_ID | 在顶点着色器输入/输出结构中定义实例 ID。 |
| UNITY_INSTANCING_BUFFER_START(bufferName) | 声明名为 bufferName 的每个实例常量缓冲区的开始。 |
| UNITY_INSTANCING_BUFFER_END(bufferName) | 声明名为 bufferName 的每个实例常量缓冲区的结尾。 |
| UNITY_DEFINE_INSTANCED_PROP(type, propertyName) | 定义具有指定类型和名称的每个实例着色器属性。 |
| UNITY_SETUP_INSTANCE_ID(v); | 允许着色器函数访问实例 ID 。对于顶点着色器,此宏在开始时是必需的。对于片段着色器,此添加是可选的。 |
| UNITY_TRANSFER_INSTANCE_ID(v, o); | 将实例 ID 从输入结构复制到顶点着色器中的输出结构。如果需要访问片段着色器中的每个实例数据,则使用此宏。 |
| UNITY_ACCESS_INSTANCED_PROP(bufferName, propertyName) | 访问实例化常量缓冲区中的每个实例着色器属性。Unity 使用实例 ID 来索引实例数据数组。 |
- 当使用多个实例属性时,无需在 MaterialPropertyBlock 对象中填充所有属性。如果一个实例缺少属性,Unity 将从引用的材质中获取默认值。如果材质没有属性的默认值,Unity 会将值设置为 0 。不要将非实例属性放在 MaterialPropertyBlock 中,因为这会禁用实例化,并且为它们创建不同的材质。
- 自定义着色器不需要每个实例数据,但需要实例 ID ,因为世界矩阵需要实例 ID 才能正常运行。表面着色器会自动设置实例 ID,但自定义顶点和片元着色器则不会。要设置自定义顶点和片元着色器的 ID,需要在着色器的开头使用 UNITY_SETUP_INSTANCE_ID 。
- 如果着色器有超过两个 pass ,Unity 只会实例化第一个 pass 。因为 Unity 会强制更改每个对象的材质,从而一起渲染后续 pass 。
- 如果使用内置的前向渲染路径,Unity 无法高效地实例化受多种光照影响的对象,只能有效地将实例化用于 base pass ,而不能用于 additional passes 。
- 对于半透明物体,由于没有对可以合并的实例对象列表进行排序,所以可能会出现混合错误的问题。
合并网格
- 手动将多个网格组合成一个网格,Unity 在单个绘制调用中渲染组合网格,而不是每个网格一个绘制调用。当网格彼此靠近且彼此不移动时,此技术可以成为绘制调用批处理的良好替代方案。然而 Unity 无法单独剔除组合的网格,这意味着,如果组合网格只有一部分在屏幕上,Unity 也将绘制整个组合网格。如果需要网格剔除,则考虑静态合批。
- 组合网格的方法有:
- 在网格制作工具中生成。
- 在 Unity 中使用 Mesh.CombineMeshes 方法。
SRP Batcher
- 官方文档说明如下:
- 优化绘制调用的传统方法是减少绘制调用的数量,相反,SRP Batcher 减少了绘制调用之间的渲染状态变化。为此,SRP Batcher 结合了一系列 bind 和 draw 的 GPU 命令,每个命令序列称为一个 SRP Batcher 。
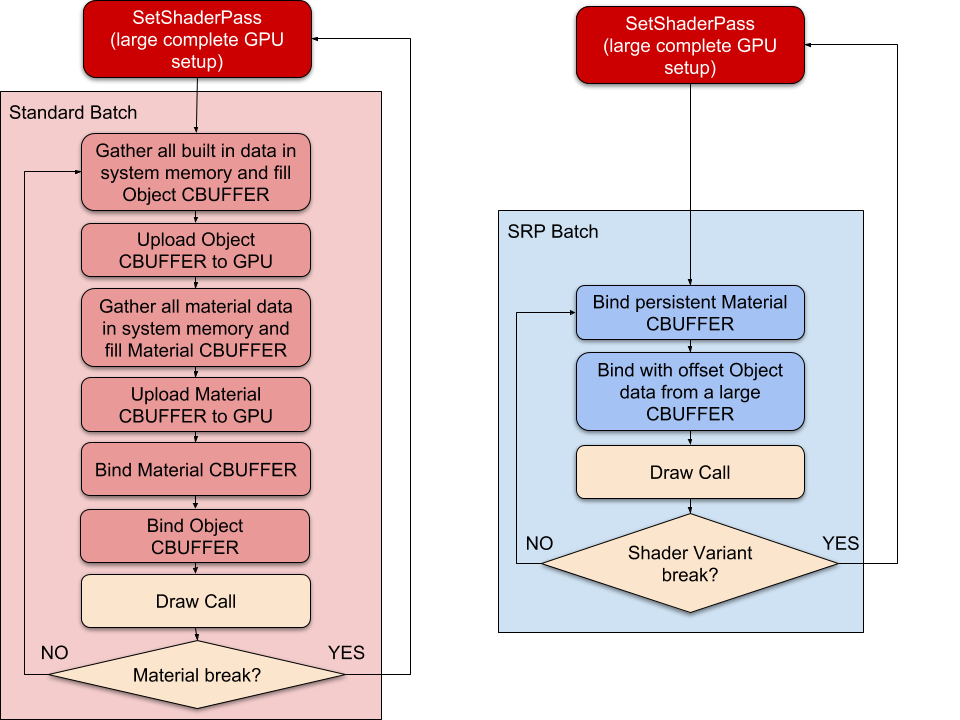
图片引自 Unity 官方文档 - 为了实现最佳渲染性能,每个 SRP 批次应包含尽可能多的 bind 和 draw 命令,为此需要尽可能少使用着色器变体,但仍然可以根据需要在同一着色器中使用尽可能多的不同材质。
- 当 Unity 在渲染循环期间检测到新材质时,CPU 会收集所有属性,并将它们绑定到常量缓冲区中的 GPU。GPU 缓冲区的数量取决于着色器如何声明其常量缓冲区。
- SRP Batcher 是一个低级渲染循环,可使材质数据保留在 GPU 内存中。如果材质内容没有变化,SRP Batcher 不会进行任何渲染状态更改。相反,SRP Batcher 使用专用代码路径在大型 GPU 缓冲区中更新 Unity Engine 属性,如图所示:
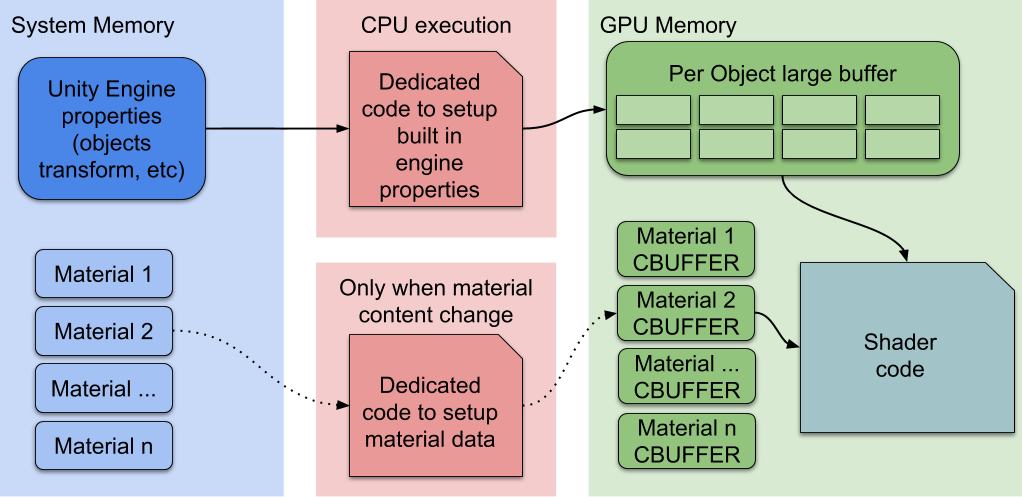
图片引自 Unity 官方文档 - 在这里,CPU 仅处理 Unity Engine 属性,在上图中标记为 Per Object large buffer ,所有材质都有位于 GPU 内存中的持久常量缓冲区,可随时使用,这可以加快渲染速度,因为:
- 所有材质内容都保留在 GPU 内存中。
- 使用专用代码管理一个大型 GPU 常量缓冲区,记录每个对象的所有属性。
- 优化绘制调用的传统方法是减少绘制调用的数量,相反,SRP Batcher 减少了绘制调用之间的渲染状态变化。为此,SRP Batcher 结合了一系列 bind 和 draw 的 GPU 命令,每个命令序列称为一个 SRP Batcher 。
- SRP Batcher 合批的对象条件如下:
- GameObject 必须包含 mesh 或 skinned mesh ,但不能是粒子(粒子系统使用动态合批)。
- 网格顶点数、顶点属性数量等都不影响合批。
- 不同组件可相互合批。
- GameObject 不能使用 MaterialPropertyBlocks 。
- shader 相同,且 shader 需要对应的代码支持:
- shader 必须在名为 UnityPerDraw 的单个常量缓冲区中声明所有内置引擎属性。例如,unity_ObjectToWorld 或 unity_SHAr 。
- shader 必须在名为 UnityPerMaterial 的单个常量缓冲区中声明所有材质属性。
- shader 不支持多 Pass(ShadowCaster/DepthOnly/Meta 等特殊 Pass 除外)。
- 材质球的 ShaderKeywords 要相同,即具有相同的个数、相同名字组合的 keyword 。
- 不同对象(具有相同 OrderInLayer)使用单/多材质球,当材质球的 RenderQueue 相同时,不同的 shader 能分别进行合批,材质球顺序不影响合批结果。
- GameObject 必须包含 mesh 或 skinned mesh ,但不能是粒子(粒子系统使用动态合批)。
总结
- 各个优化的对比如下表:
| 类型 | Draw Call 数量 | SetPass Call 数量 | Batch 数量 | 应用场景 |
|---|---|---|---|---|
| 静态合批 | 下降(网格顶点连续时) | 下降 | 下降 | 材质相同,网格不相同的静态物体 |
| 动态合批 | 下降 | 下降 | 下降 | 材质相同,顶点数较少,网格不相同的物体 |
| 合并网格 | 下降 | 下降 | 下降 | 材质相同,网格之间相对静止且不需要部分剔除的物体 |
| GPU Instancing | 下降 | 下降 | 下降 | 材质相同,网格相同,顶点数量超过 256 ,物体数量较多 |
| SRP Batcher | 不变 | 下降 | 下降 | shader 相同,非粒子网格 |
-
Unity 对绘制调用优化的优先级排序为:
- SRP Batcher 和静态合批。
- GPU Instancing 。
- 动态合批。
-
Demo示例工程(Unity2020.3): https://github.com/FallingXun/Demo/tree/main/DrawCallOptimization