蒙皮动画是游戏中常用的动画技术,随着动画数量的增加,动画的耗时会增加,在移动设备上需要进行优化。
简介
- 游戏开发中,为了呈现变化的表现,动画是不可或缺的。随着移动端硬件设备的逐步升级,游戏中的动画需求也慢慢从 2D 帧动画转变到 3D 蒙皮动画。然而,由于移动端设备的性能瓶颈,对于 同屏出现的大量 3D 动画,往往表现不佳。为了追求同屏高数量的表现,可以使用 GPU Skinning 技术对动画进行优化。在了解该技术前,需要先了解蒙皮动画的相关内容。
蒙皮动画
- 蒙皮动画主要由骨骼(skeleton)和皮肤(skin)组成。
- 骨骼是由刚性的骨头(bone)组成,骨头两端为关节(joint)。通过关节的变换,可以实现各种动作行为,而骨骼本身不会进行渲染显示。
- 皮肤是三角形网格,绑定在骨骼上,跟随关节的变换进行变形,产生接近真实的皮肤和衣着移动。
关节
- 实际应用中,通常不会使用骨头概念,而是使用关节,因为真正进行旋转移动的是关节。选择一个关节为根,则其他关节为其子节点或后代节点,从而可以组成一个骨骼层级,即树结构。例如,人物角色的骨骼结构可能为:
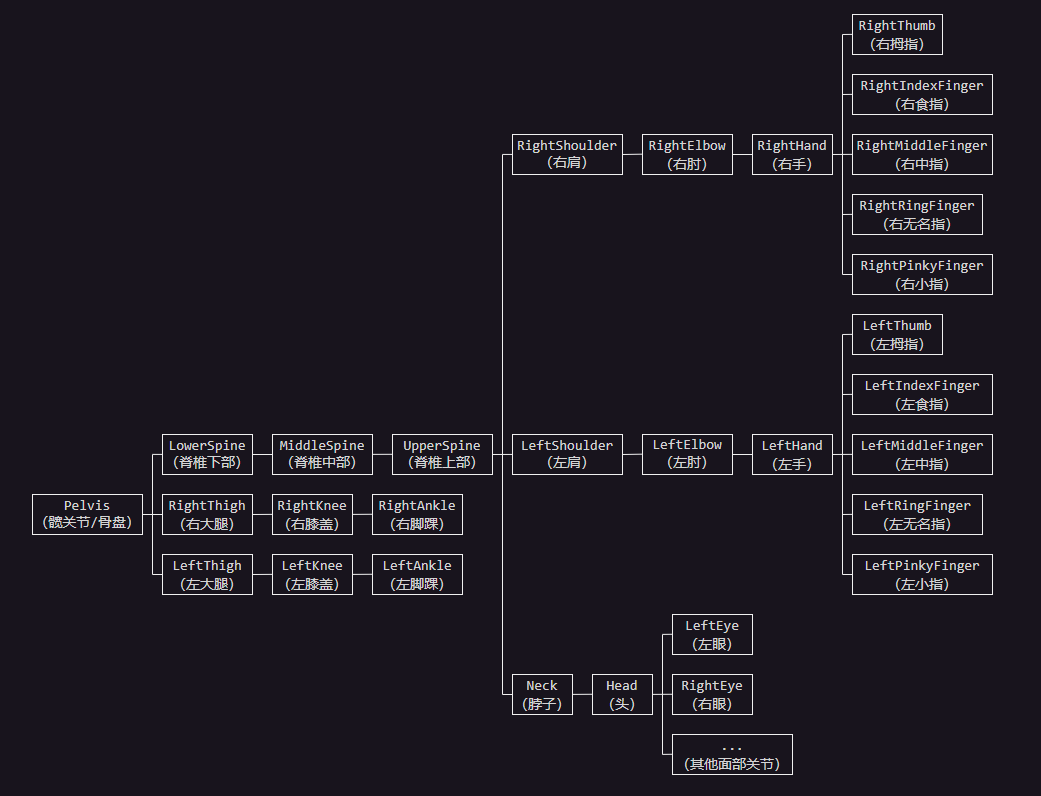
- 每个关节有且只有一个父节点,存储的数据主要有两个:
- 索引值:关节的标识,用于定位和查找。
- 绑定姿势逆矩阵:绑定姿势是指,蒙皮网格顶点绑定到骨骼上时,关节在模型空间下的位置、旋向、缩放信息,通过绑定姿势可以得到关节的局部空间到模型空间的变换矩阵,保存时使用逆矩阵。
姿势
- 把关节按照任意旋转、平移、缩放,就能为骨骼摆出各种姿势。一个关节的姿势定义为关节相对某个参考坐标系的位子、旋向和缩放,通常以 4x4 或 4x3 矩阵表示。
- 其中,绑定姿势是一个特殊的姿势,是三维网格绑定到骨骼之前的姿势,由于这个姿势下角色通常双腿稍分开站着,双臂向两侧伸直,形成 T 字形,所以又叫 T 姿势。在此姿势下,四肢远离身体,比较容易把网格顶点绑定到关节。
蒙皮矩阵
- 网格顶点绑定到关节后,在该关节空间中是保持不变的。前面提到通过绑定姿势可以得到关节的局部空间到模型空间的变换矩阵,也是基于这一点。
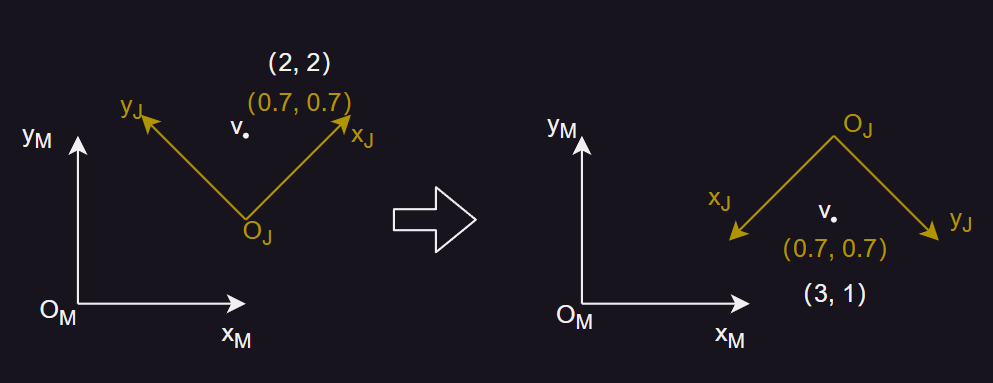
- 如图中所示,M 表示模型空间,J 表示关节空间。当顶点绑定到骨骼上后,对关节进行变换,在模型空间下,该顶点的位置、旋向、缩放发生了变化,而在该关节空间下的仍保持不变。
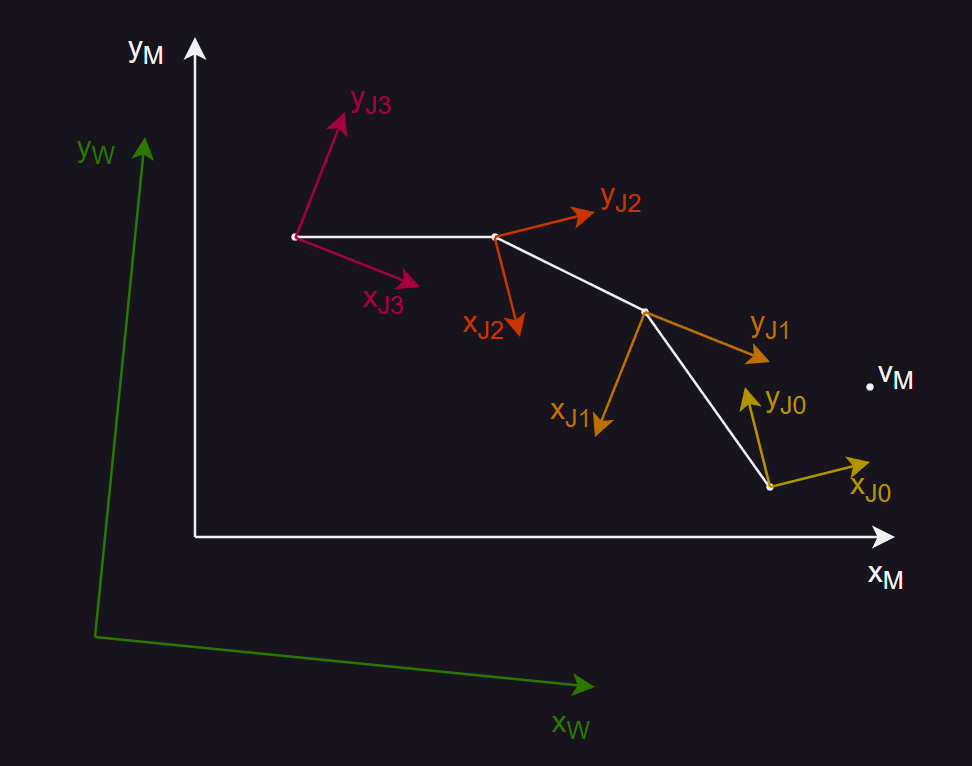
- 上图白色表示一个骨骼,顶点 v 绑定到骨骼上。J3 是根关节,W 是世界空间。将骨骼蒙皮后,导出到游戏引擎后,最终使用的坐标空间就是 W ,根关节的信息也会变成 W 下的信息。此时,为了进行渲染,需要得到顶点 v 在 世界空间 W 下的信息。然而,在蒙皮过程中,顶点存储的是模型空间下的信息,需要将其转换为其关节空间下的信息,再逐级变换到父关节空间,直到变换根关节空间下的后,再跟进根关节在世界空间下的信息,将 v 的信息变换到世界空间下进行计算。
- 因此,需要得到模型空间到顶点绑定的关节空间的变换矩阵,即关节空间到模型空间的变换矩阵的逆矩阵,因此关节中会直接存储逆矩阵数据,从而减少求逆计算过程,则蒙皮矩阵可以表示为:
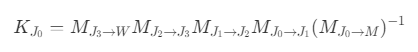
- 如果将模型导入到游戏引擎 Unity 后,根关节的信息即为世界空间下的信息,由于 Unity 中的每个 Transform 都已经提供了局部空间变换到世界空间的变换矩阵(localToWorldMatrix),因此绑定姿势逆矩阵变换后得到的关节局部空间,可以直接变换到世界空间,省去了中间逐级转换的过程,则蒙皮矩阵可以表示为:
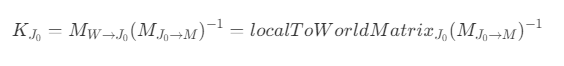
权重
- 如果顶点绑定到一个关节上,就会完全跟随该关节移动。然而很多时候,顶点会绑定到多个关节上,收到多个关节的组合影响进行变化。每个关节对顶点的影响不一,因此需要计算出该顶点变换到各个关节后的位置,再进行加权平均,得到该顶点最终的信息。
- 通常游戏引擎会限制每个顶点最多能绑定 4 个关节,原因如下:
- 4 个 8 位关节索引,方便通过用一个 32 位结构存储。
- 每个顶点绑定 2 个、3个、4个关节时,产生的效果很容易区分,但对于 4 个关节以上的的效果,大部分人不能分辨出来其差别。
- 因此,蒙皮后的网格顶点需要保存其绑定的关节索引,以及对应的权重因子,所有权重之和始终为 1 ,蒙皮矩阵为:
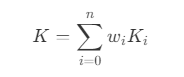
GPUSkinning
- 动画文件会对每一帧中各个关节的位置、旋向、缩放进行设置,运行时进行更新,对网格顶点进行变换。这些处理通常在 CPU 中完成,再将处理后的顶点信息传递到 GPU 中进行渲染。
- 当场景中出现大量对象播放动画时,就会有较大的性能开销,在移动端上更是如此。可以看到,CPU 处理动画的主要工作是进行顶点信息的变换计算,而这一块就占用了不少资源。相对来说,GPU 的处理速度要远比 CPU 快得多,因为 GPU 是高度专用化的,能处理大量的并行计算,并有非常高的并行存储访问。因此,往往 GPU 不容易达到瓶颈,通常是在处理完 CPU 提交的任务后,处于等待下一批任务提交的状态。
- 为了充分利用 GPU 的优势,同时也减轻 CPU 的压力,GPUSkinning 将顶点变换的过程放到了 GPU 中处理,主要包括离线数据生成和运行时计算。
离线数据生成
- 为了计算出顶点在世界空间下的坐标,需要得到关节对应的蒙皮矩阵、顶点绑定的关节索引、顶点绑定关节的权重三个信息,其中,顶点绑定的关节索引和对应的权重信息是固定的,存储在网格信息中,可直接读取。而关节对应的蒙皮矩阵,则会随着每一帧的动画变化而发生改变,因此,需要根据需求确定关键帧或指定帧,采样得到当前帧所有关节的信息,再计算出每个关节的蒙皮矩阵。
- 所有数据都已经得到了,就需要对数据进行存储。
- 每个顶点最多绑定 4 个关节,因此需要存储 4 个索引和 4个权重。索引和权重可以用 float 表示,则共计 8 个 float 值,由于是顶点需要的数据,所以可以直接使用顶点的 2 个 uv 来保存。
- 每个蒙皮矩阵为 4x4 矩阵,由于蒙皮矩阵是关节对应的,所以需要转成纹理保存,每个矩阵使用 4 个像素的 RGBA 来表示,将每个动作的每一帧连续写入。纹理格式需要使用 RGBAHalf 或者精度更大的格式,避免精度不足导致出现太大的误差。
运行时计算
- 运行时的计算流程在顶点着色器中,主要步骤为:
- CPU 将当前需要播放的动作起止帧索引,以及当前时间需要播放第几帧,传到 GPU 中。
- 通过顶点 uv 读取当前顶点绑定的所有关节索引及对应权重。
- 计算当前动作当前帧需要采样的纹理 uv 。
- 采样离线生成的矩阵纹理,得到蒙皮矩阵信息。
- 由于在顶点着色器中进行采样,无法使用 tex2D 方法,需要改为使用 tex2Dlod 方法。
- 使用蒙皮矩阵对顶点坐标、法线、切线进行变换,得到当前空间下的对应信息。
- 将变换后的信息传到像素着色器中,采样模型纹理并输出最终颜色。
- 如果使用了实时阴影,生成 ShadowMap 时,需要对应的顶点、法线数据,所以需要在另一个 Pass 中进行采样计算,因此采样次数会翻倍。由于阴影不需要有那么多显示细节,所以可以选择使用简化后的网格,从而可以减少采样次数。而骨骼可以沿用,因此矩阵纹理可以共用。
优化方案
uv坐标计算
- 采样骨骼动画的 uv 坐标,通过当前帧数和当前骨骼索引可以计算得到。每根骨骼的变换矩阵,需要采样 4 个 uv 坐标,即 uv 坐标需要计算 4 次,计算中需要使用除法或者求余计算。
- 由于变换矩阵的 4 个 uv 坐标通常是相邻的,如果保证骨骼动画纹理图的尺寸是 4 的倍数,则只要计算一次得到首个 uv ,再通过累加一个纹素的尺寸,就能得到下一个 uv 坐标,这样就能减少多次除法和求余的计算过程,降低计算压力。
- 此外,由于变换矩阵的最后一行通常为 (0, 0, 0, 1) ,所以最后一行可以不用进行采样,减少采样频率,但骨骼动画中还是会写入,保证每个变换矩阵是占 4 个颜色值,避免纹理出现奇数。
half4x4 loadMatrix(uint frameIndex, uint boneIndex, float texelSizeX, float texelSizeY)
{
uint index = frameIndex * _BoneCount + boneIndex;
half x = index % _Width * texelSizeX;
half y = index / _Width * 4 * texelSizeY;
half4 uv = half4(x, y, 0, 0);
half4 c0 = tex2Dlod(_AnimationTex, uv);
uv.y = uv.y + texelSizeY;
half4 c1 = tex2Dlod(_AnimationTex, uv);
uv.y = uv.y + texelSizeY;
half4 c2 = tex2Dlod(_AnimationTex, uv);
half4 c3 = half4(0, 0, 0, 1);
half4x4 m = half4x4(c0, c1, c2, c3);
return m;
}
缓存命中
- 当 GPU 访问一个纹素时,很大可能会访问同个位置或者相邻的纹素,因此 GPU 通常会以 n x n 的块状对纹理数据进行缓存,从而提高缓存命中几率。
- 存储骨骼动画的时候,纹理通常是按行写入,此时对一个顶点的 4 根骨骼进行采样时,由于骨骼索引值不一定连续,所以对每根骨骼采样时,GPU 很容易出现需要重新加载新的一块数据到缓存中,从而造成采样效率低下。
- 因此,可以将每根骨骼每一帧的数据纵向写入到纹理中,从而尽可能保证同一块缓存中具有多根骨骼的数据,减少重新加载的频率。
- Hakura 和 Gupta 研究发现,当块的大小和缓存行一样大时,即 128KB 和 256KB ,缓存命中率越高,此时对应的块的大小为 8 x 8 和 16 x 16 。
- 一些 GPU 还会以 Z 顺序存储纹理贴图,则缓存行中的连续数据代表一个矩形图块,从而增加附近访问位于缓存中的概率,这种方式成为 Z-order curve 或 Morton order 。
采样次数
- 尽管 unity 默认为每个顶点提供了 4 根骨骼的数据结构,但并不是每个顶点都需要使用 4 根骨骼。通常情况下,很多顶点只需要使用 1 根或者 2 根骨骼,也就是说,会出现无效的纹理采样过程,而纹理采样通常是耗时较高的过程:
- 采样过程需要 GPU 中的硬件单元读取纹理数据,再传递给着色器处理,由于涉及硬件操作,所以会比纯粹的计算操作慢。
- 纹理通常以二维图像的形式存在显存中,则采样时需要对显存进行读写操作。
- 采样过程可能会应用纹理过滤(双线性插值、三线性插值)来处理纹理坐标不在整数像素点的情况。
- 纹理大小会影响纹理的缓存命中,插值过滤的过程需要采样的数据量也会随着纹理变大而增多。
- 因此,GPU Gems 中给出了一个优化方案,即将顶点骨骼索引按照权重从大到小进行排序,如果某根骨骼权重为 0 ,则后续骨骼都不需要进行采样,即
half4x4 mat = (loadMatrix(curFrame, i.uv2.x, texelSizeX, texelSizeY) * i.uv2.y);
if (i.uv2.w > 0) {
mat += (loadMatrix(curFrame, i.uv2.z, texelSizeX, texelSizeY) * i.uv2.w);
if (i.uv3.y > 0) {
mat += (loadMatrix(curFrame, i.uv3.x, texelSizeX, texelSizeY) * i.uv3.y);
if (i.uv3.w > 0) {
mat += (loadMatrix(curFrame, i.uv3.z, texelSizeX, texelSizeY) * i.uv3.w);
}
}
}
- 尽管出现了 if 分支,可能会导致 GPU 的并行处理效率降低,相较于纹理采样,总体上来讲还是能提高运行效率的。
- 对顶点的骨骼按权重进行排序后,如果当前骨骼的权重为 0 ,则可以将当前骨骼的索引设置为上一个权重不为 0 的索引,则采样的时候,会和上一根骨骼使用同样的 uv 进行采样,则可能不需要进行真正的采样过程,而是通过直接读取缓存就能得到结果。
for (int i = 0; i < skr.sharedMesh.vertexCount; i++)
{
var boneWeight = skr.sharedMesh.boneWeights[i];
boneIndex[0] = boneWeight.boneIndex0;
boneIndex[1] = boneWeight.weight1 > 0 ? boneWeight.boneIndex1 : boneIndex[0];
boneIndex[2] = boneWeight.weight2 > 0 ? boneWeight.boneIndex2 : boneIndex[1];
boneIndex[3] = boneWeight.weight3 > 0 ? boneWeight.boneIndex3 : boneIndex[2];
var uv2 = new Vector4(boneIndex[0], boneWeight.weight0, boneIndex[1], boneWeight.weight1);
var uv3 = new Vector4(boneIndex[2], boneWeight.weight2, boneIndex[3], boneWeight.weight3);
uv2s.Add(uv2);
uv3s.Add(uv3);
}
采样频率
- 通常每秒会采样 30 帧,能得到一个比较好的动画效果。然而,采样 30 帧得到的矩阵数量是采样 15 帧的两倍,所以得到的纹理图通常会比较大。相对的,如果只采样 15 帧,则动画会出现明显的卡顿感。
- 为了解决卡顿感,可以采用插值的方式,即每次会对当前帧和下一帧的骨骼动画进行采样,然后将顶点、法线、切线进行变换后,再分别进行插值。
frame = frame + 1;
int nextFrame = lerp(clamp(frame, 0, count - 1), (frame % count), loop) + start;
half4x4 mat2 = (loadMatrix(nextFrame, i.uv2.x, texelSizeX, texelSizeY) * i.uv2.y);
mat2 += (loadMatrix(nextFrame, i.uv2.z, texelSizeX, texelSizeY) * i.uv2.w);
mat2 += (loadMatrix(nextFrame, i.uv3.x, texelSizeX, texelSizeY) * i.uv3.y);
mat2 += (loadMatrix(nextFrame, i.uv3.z, texelSizeX, texelSizeY) * i.uv3.w);
float4 vertex2 = mul(mat2, i.vertex);
float3 normal2 = mul((half3x3)mat2, i.normal.xyz);
float4 tangent2 = mul(mat2, i.tangent);
float l = frac(frameTime);
i.vertex = lerp(vertex, vertex2, l);
i.normal = normalize(lerp(normal, normal2, l));
i.tangent = normalize(lerp(tangent, tangent2, l));
阴影计算
- 阴影计算需要额外的 Pass ,其中顶点坐标计算还是需要对骨骼动画进行采样,但是相对可以有一些优化:
- 常规渲染时,每个顶点需要采样 4 根骨骼,使用插值时则需要采样 8 根骨骼。但阴影精确度可以不需要那么高,并且最终是投射到接收面上,所以可以只采样权重最高的 1 ~ 2 根骨骼,来降低采样计算消耗。
- 法线、切线可以不需要进行计算,减少计算量。
// 动画不循环,播完则停在最后一帧
int curFrame = lerp(clamp(frame, 0, count - 1), (frame % count), loop) + start;
half4x4 mat = (loadMatrix(curFrame, i.uv2.x, texelSizeX, texelSizeY) * i.uv2.y);
float4 vertex = mul(mat, i.vertex);
#ifdef GPUSKINNING_LERP
// 如果开启插值,则需要采样下一帧的状态,再进行插值
frame = frame + 1;
int nextFrame = lerp(clamp(frame, 0, count - 1), (frame % count), loop) + start;
half4x4 mat2 = (loadMatrix(nextFrame, i.uv2.x, texelSizeX, texelSizeY) * i.uv2.y);
float4 vertex2 = mul(mat2, i.vertex);
float l = frac(frameTime);
i.vertex = lerp(vertex, vertex2, l);
#else
i.vertex = vertex;
#endif
性能对比
- Animator 和 GPUSkinning 的性能对比如下:
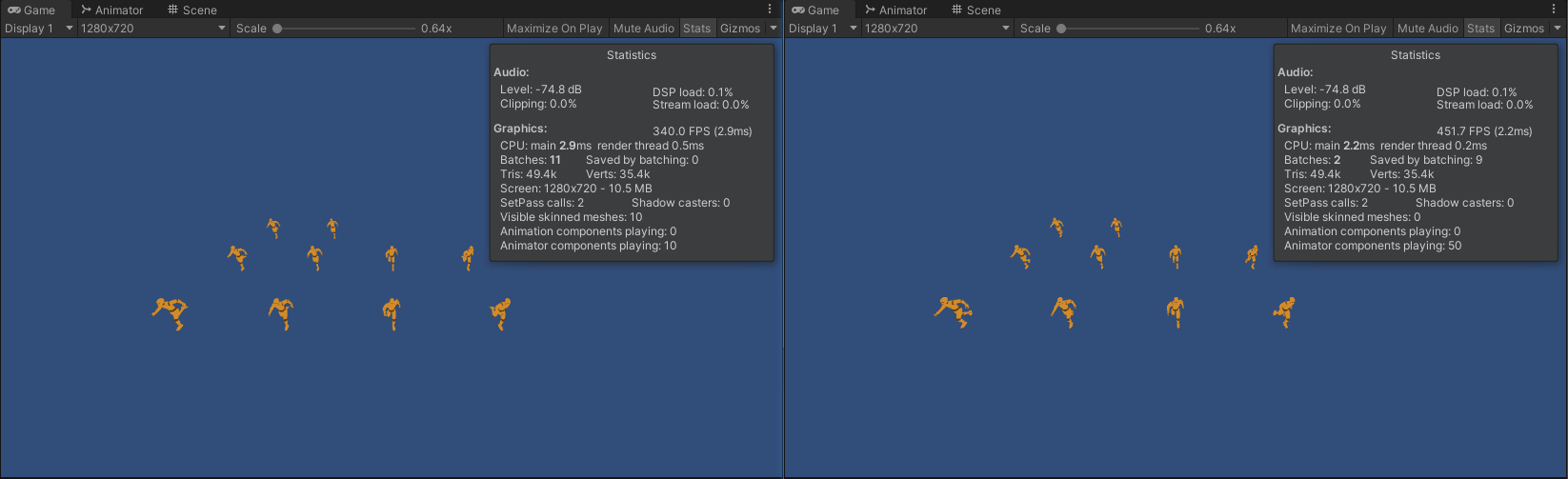
左:Animator(10) 右:GPUSkinning(10) 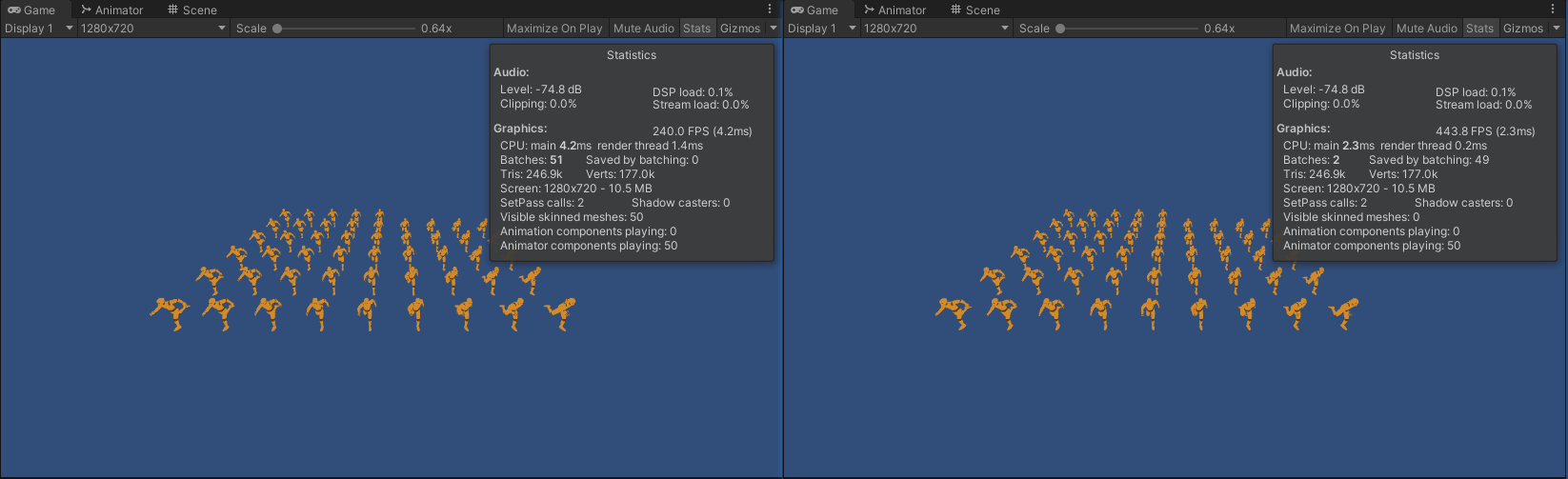
左:Animator(50) 右:GPUSkinning(50) 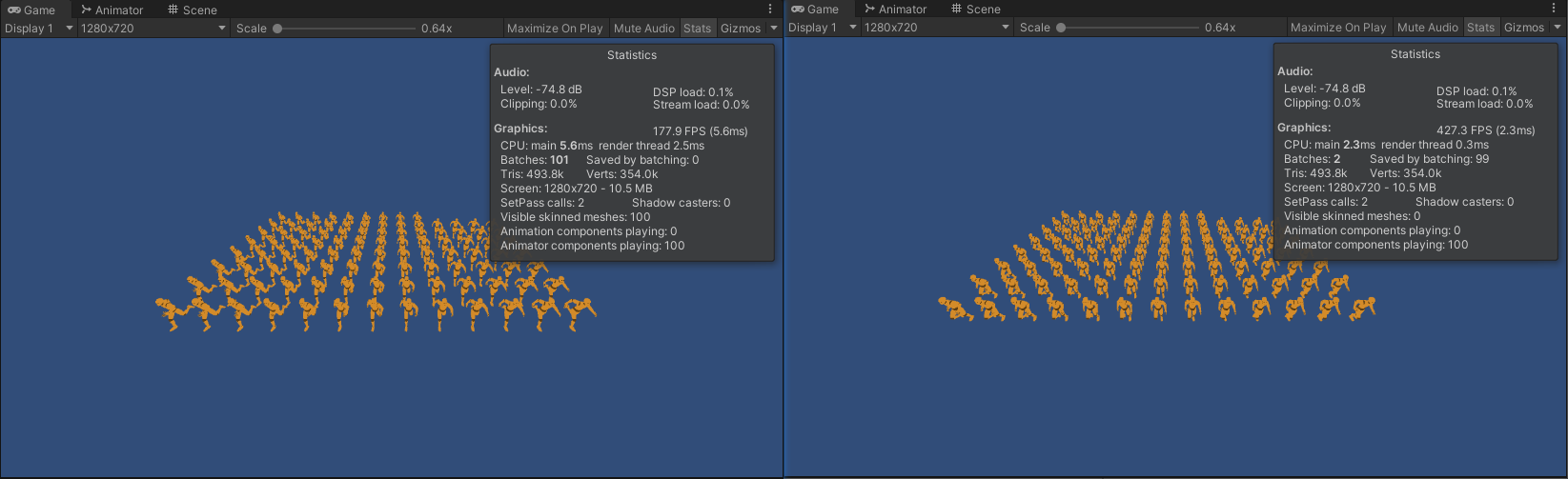
左:Animator(100) 右:GPUSkinning(100)
左:Animator(500) 右:GPUSkinning(500) 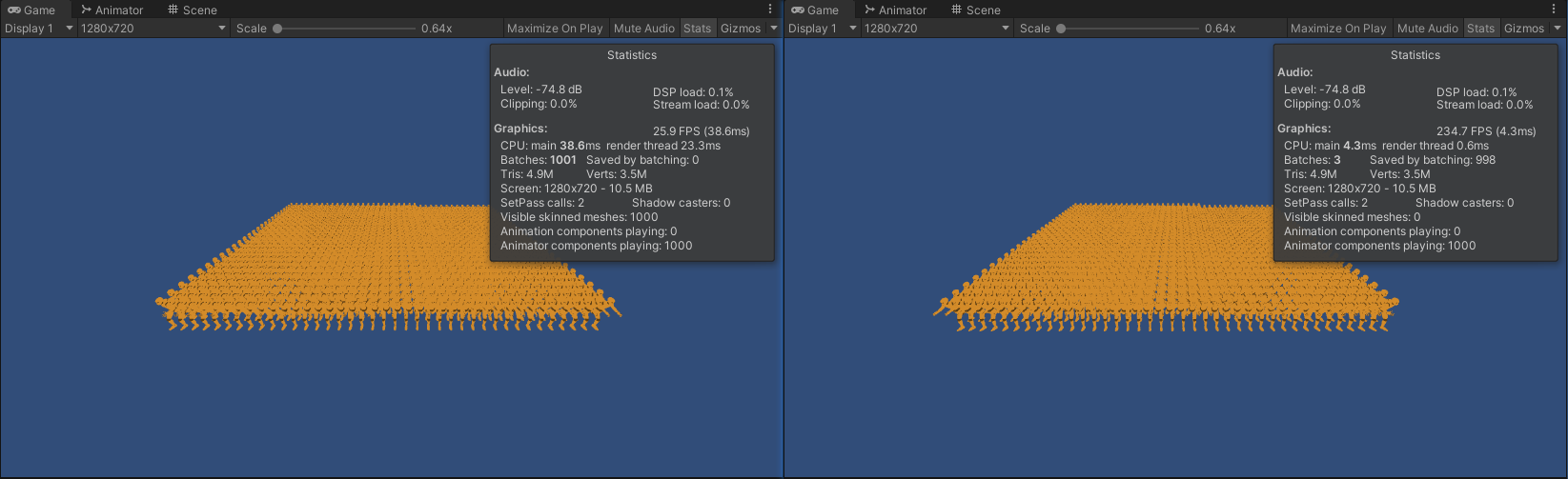
左:Animator(1000) 右:GPUSkinning(1000) - 当模型数量较少时,渲染耗时优化程度较小,但批次可以合并。
- 当模型数量较多时,渲染耗时优化程度非常大,并且批次数量也得到了大幅度减少。
示例工程
参考
- 游戏引擎架构
- GPUSkinning github
- Animation-Instancing github
- Texture Caches
- Z-order curve
- GPU Gems3 - Chapter 2. Animated Crowd Rendering