lua 表是 lua 中的非常常用的结构,本文将以 lua-5.4.1 版本进行源码解析。
简介
- 在 C# 中,有数组、字典等数据结构,用于存储一批数据并提供快速查询的方法。而在 lua 中,则通过表(table),来实现类似的数据结构。
数据结构
- 在 lua 中,table 的数据结构为:
// lobject.h
typedef struct Table {
CommonHeader;
lu_byte flags; /* 1<<p means tagmethod(p) is not present */
lu_byte lsizenode; /* log2 of size of 'node' array */
unsigned int alimit; /* "limit" of 'array' array */
TValue *array; /* array part */
Node *node;
Node *lastfree; /* any free position is before this position */
struct Table *metatable;
GCObject *gclist;
} Table;
- Table 的参数含义为:
- CommonHeader :需要 gc 的对象的公共头部。
- flags :表中拥有的方法标识,方法类型定义在 TMS 枚举(ltm.h)中。
- lsizenode :node 长度对 2 取对数。
- alimit :array 的数量上限。
- array :数组部分。
- node :哈希表部分。
- lastfree :上一个空闲节点。
- metatable :元表。
- gclist :gc 相关信息。
- 可以看到,在 lua 中的表,是一个复合结构,同时具有数组和哈希表的功能,后面将介绍其具体实现。
创建 table
- lua 创建新表的方法为:
// lapi.c
LUA_API void lua_createtable (lua_State *L, int narray, int nrec) {
Table *t;
lua_lock(L);
t = luaH_new(L);
sethvalue2s(L, L->top, t);
api_incr_top(L);
if (narray > 0 || nrec > 0)
luaH_resize(L, t, narray, nrec);
luaC_checkGC(L);
lua_unlock(L);
}
- 创建新表的主要流程为:
- 调用 luaH_new 创建一个 Table 对象。
- 将 Table 对象设置到栈上。
- 移动栈顶到下一个位置。
- 根据传入的数组长度和哈希表长度,重新设置表对象的大小。
- luaH_new 的方法为:
// ltable.c
Table *luaH_new (lua_State *L) {
GCObject *o = luaC_newobj(L, LUA_VTABLE, sizeof(Table));
Table *t = gco2t(o);
t->metatable = NULL;
t->flags = cast_byte(maskflags); /* table has no metamethod fields */
t->array = NULL;
t->alimit = 0;
setnodevector(L, t, 0);
return t;
}
- 创建 Table 对象时,元表默认为空,flags 设置为 maskflags ,从右往左前 6 位为 1 ,其他位为 0 ,其中,第 8 位用于代表当前 alimit 是否为数组的真实上限。
- table 的主要对象即为数组和哈希表部分。创建时,数组设置为 NULL ,数组上限大小也为 0 。
哈希表初始化
- 哈希表通过 setnodevector 进行初始化:
// ltable.c
static void setnodevector (lua_State *L, Table *t, unsigned int size) {
if (size == 0) { /* no elements to hash part? */
t->node = cast(Node *, dummynode); /* use common 'dummynode' */
t->lsizenode = 0;
t->lastfree = NULL; /* signal that it is using dummy node */
}
else {
int i;
int lsize = luaO_ceillog2(size);
if (lsize > MAXHBITS || (1u << lsize) > MAXHSIZE)
luaG_runerror(L, "table overflow");
size = twoto(lsize);
t->node = luaM_newvector(L, size, Node);
for (i = 0; i < (int)size; i++) {
Node *n = gnode(t, i);
gnext(n) = 0;
setnilkey(n);
setempty(gval(n));
}
t->lsizenode = cast_byte(lsize);
t->lastfree = gnode(t, size); /* all positions are free */
}
}
- 空的哈希表,lsizenode 为 0 ,则最小尺寸为 1 ,为了减少空表的 node 节点,因此创建了一个不可修改的静态节点 dummynode ,将空表的 node 指向 dummynode 。
// ltable.c
#define dummynode (&dummynode_)
static const Node dummynode_ = {
{{NULL}, LUA_VEMPTY, /* value's value and type */
LUA_VNIL, 0, {NULL}} /* key type, next, and key value */
};
static const TValue absentkey = {ABSTKEYCONSTANT};
- 对于非空的哈希表,则根据传入的尺寸 size ,向上取对数值,得到对数尺寸 lsizenode ,并申请对应的 Node 数组内存,对数组进行初始化赋值。
存入 table
- 向 table 中写入值,可以通过调用 lua_settable 方法进行,其代码如下:
// lapi.c
LUA_API void lua_settable (lua_State *L, int idx) {
TValue *t;
const TValue *slot;
lua_lock(L);
api_checknelems(L, 2);
t = index2value(L, idx);
if (luaV_fastget(L, t, s2v(L->top - 2), slot, luaH_get)) {
luaV_finishfastset(L, t, slot, s2v(L->top - 1));
}
else
luaV_finishset(L, t, s2v(L->top - 2), s2v(L->top - 1), slot);
L->top -= 2; /* pop index and value */
lua_unlock(L);
}
// lvm.c
#define luaV_fastget(L,t,k,slot,f) \
(!ttistable(t) \
? (slot = NULL, 0) /* not a table; 'slot' is NULL and result is 0 */ \
: (slot = f(hvalue(t), k), /* else, do raw access */ \
!isempty(slot))) /* result not empty? */
- 先通过 luaV_fastget 方法,对于 table 类型的对象,调用传入的获取方法 luaH_get 进行查找,找到对应位置如果数据不为空,则当前 key 值已经存在,需要将新的值更新到对应的位置中。如果不存在,则调用 luaV_finishset 进行新增 key 值相关处理。
查找存入位置更新现有 key
- 查找 key 值的方法如下:
// ltable.c
const TValue *luaH_get (Table *t, const TValue *key) {
switch (ttypetag(key)) {
case LUA_VSHRSTR: return luaH_getshortstr(t, tsvalue(key));
case LUA_VNUMINT: return luaH_getint(t, ivalue(key));
case LUA_VNIL: return &absentkey;
case LUA_VNUMFLT: {
lua_Integer k;
if (luaV_flttointeger(fltvalue(key), &k, F2Ieq)) /* integral index? */
return luaH_getint(t, k); /* use specialized version */
/* else... */
} /* FALLTHROUGH */
default:
return getgeneric(t, key);
}
}
- 可以看到,对于传入的 key 值,根据不同类型进行 hash 计算后进行查找。其中,key 值为 float 类型的,会检查是否能转成 int 类型,使用 int 类型进行查找。而对于非 int 类型的,都是直接根据 hash 计算结果,在哈希表中查找。而 int 类型的 key ,则会在数组部分和哈希表部分中查找。
// ltable.c
const TValue *luaH_getint (Table *t, lua_Integer key) {
if (l_castS2U(key) - 1u < t->alimit) /* 'key' in [1, t->alimit]? */
return &t->array[key - 1];
else if (!limitequalsasize(t) && /* key still may be in the array part? */
(l_castS2U(key) == t->alimit + 1 ||
l_castS2U(key) - 1u < luaH_realasize(t))) {
t->alimit = cast_uint(key); /* probably '#t' is here now */
return &t->array[key - 1];
}
else {
Node *n = hashint(t, key);
for (;;) { /* check whether 'key' is somewhere in the chain */
if (keyisinteger(n) && keyival(n) == key)
return gval(n); /* that's it */
else {
int nx = gnext(n);
if (nx == 0) break;
n += nx;
}
}
return &absentkey;
}
}
- 查找过程有几种情况:
- 如果索引 key 值,在数组上限数量 alimit 内,则数据直接存入数组对应索引位置中。
- 如果数组上限数量 alimit 不为真实上限,但索引 key 值仍然在数组部分的真实上限内,同样存入数组对应索引的位置中。
- 如果索引超过数组上限,则需要对索引 key 做 hash 计算,得到哈希表 node 的链表节点,遍历链表节点,找到节点的 key 值和索引相同的,该节点即为要存入数据的位置。
- 如果没有找到对应节点,则返回一个常量位置,表示该索引 key 缺少可以存入的位置。
- 其中,索引 hash 计算的方法为:
// ltable.c
#define hashpow2(t,n) (gnode(t, lmod((n), sizenode(t))))
...
#define hashint(t,i) hashpow2(t, i)
- hashint 计算,就是将索引 key 对哈希表长度取模。由于哈希表的长度 size 为 2 的指数次幂,因此 size - 1 的有效位为连续的 1 ,则取模的结果是连续的,每一个有效位的 0 和 1 的出现概率都是相同的,一定程度上能得到均匀分布的结果。
- 如果 size = 4,则 size - 1 二进制有效位表示为 11,取模结果有 00 、01 、10 、11 ,每一个有效位的 0 和 1 的出现概率都为 1/2 ,11 的下一个结果即为 00,保持有效位上的连续性。
- 如果 size = 5 ,则 size - 1 二进制有效位表示为 100,则取模结果有 000 、001 、010 、011 、100 ,第一位出现 1 的概率为 1/5 ,第二位为 2/5 ,第三位为 2/5 ,100 的下一个结果不是 101 ,而是直接跳到 000 ,即有效位上不连续。
- 此外,对于一些长字符串,hash 计算的结果可能很大,而取模时,只需要对后几位有效位进行计算即可得到结果,因此也提高了取模的计算效率。
- 因此,lsizenode 使用 2 的对数结果来保存长度,来保证哈希表长度是 2 的指数次幂。
分配存入位置添加新 key
- 经过查找后,没有找到位置,则需要重新进行分配后写入。
// lvm.c
void luaV_finishset (lua_State *L, const TValue *t, TValue *key,
TValue *val, const TValue *slot) {
int loop; /* counter to avoid infinite loops */
for (loop = 0; loop < MAXTAGLOOP; loop++) {
const TValue *tm; /* '__newindex' metamethod */
if (slot != NULL) { /* is 't' a table? */
Table *h = hvalue(t); /* save 't' table */
lua_assert(isempty(slot)); /* slot must be empty */
tm = fasttm(L, h->metatable, TM_NEWINDEX); /* get metamethod */
if (tm == NULL) { /* no metamethod? */
if (isabstkey(slot)) /* no previous entry? */
slot = luaH_newkey(L, h, key); /* create one */
/* no metamethod and (now) there is an entry with given key */
setobj2t(L, cast(TValue *, slot), val); /* set its new value */
invalidateTMcache(h);
luaC_barrierback(L, obj2gco(h), val);
return;
}
/* else will try the metamethod */
}
else { /* not a table; check metamethod */
tm = luaT_gettmbyobj(L, t, TM_NEWINDEX);
if (unlikely(notm(tm)))
luaG_typeerror(L, t, "index");
}
/* try the metamethod */
if (ttisfunction(tm)) {
luaT_callTM(L, tm, t, key, val);
return;
}
t = tm; /* else repeat assignment over 'tm' */
if (luaV_fastget(L, t, key, slot, luaH_get)) {
luaV_finishfastset(L, t, slot, val);
return; /* done */
}
/* else 'return luaV_finishset(L, t, key, val, slot)' (loop) */
}
luaG_runerror(L, "'__newindex' chain too long; possible loop");
}
- 可以看到,为新的 key 值分配位置时,是否有元表,会进行不同处理。
- 当前 table 没有元表,或者元表没有 __newindex ,如果有找到未赋值的空闲位置,进行赋值,如果没有找到空闲位置,则调用 luaH_newkey 方法为新的 key 值分配位置后赋值。
- 当前 table 元表 __newindex 为方法,调用 __newindex 方法进行分配位置后赋值。
- 当前 table 元表 __newindex 不为方法,则在 __newindex 中进行查找位置。
- 如果找到位置,则进行赋值。
- 如果找不到位置,则将 __newindex 传入 luaV_finishset ,递归调用,直到分配到位置后进行赋值(调用上限为 2000 次)。
- luaH_newkey 的代码如下:
// ltable.c
TValue *luaH_newkey (lua_State *L, Table *t, const TValue *key) {
Node *mp;
TValue aux;
if (unlikely(ttisnil(key)))
luaG_runerror(L, "table index is nil");
else if (ttisfloat(key)) {
lua_Number f = fltvalue(key);
lua_Integer k;
if (luaV_flttointeger(f, &k, F2Ieq)) { /* does key fit in an integer? */
setivalue(&aux, k);
key = &aux; /* insert it as an integer */
}
else if (unlikely(luai_numisnan(f)))
luaG_runerror(L, "table index is NaN");
}
mp = mainpositionTV(t, key);
if (!isempty(gval(mp)) || isdummy(t)) { /* main position is taken? */
Node *othern;
Node *f = getfreepos(t); /* get a free place */
if (f == NULL) { /* cannot find a free place? */
rehash(L, t, key); /* grow table */
/* whatever called 'newkey' takes care of TM cache */
return luaH_set(L, t, key); /* insert key into grown table */
}
lua_assert(!isdummy(t));
othern = mainposition(t, keytt(mp), &keyval(mp));
if (othern != mp) { /* is colliding node out of its main position? */
/* yes; move colliding node into free position */
while (othern + gnext(othern) != mp) /* find previous */
othern += gnext(othern);
gnext(othern) = cast_int(f - othern); /* rechain to point to 'f' */
*f = *mp; /* copy colliding node into free pos. (mp->next also goes) */
if (gnext(mp) != 0) {
gnext(f) += cast_int(mp - f); /* correct 'next' */
gnext(mp) = 0; /* now 'mp' is free */
}
setempty(gval(mp));
}
else { /* colliding node is in its own main position */
/* new node will go into free position */
if (gnext(mp) != 0)
gnext(f) = cast_int((mp + gnext(mp)) - f); /* chain new position */
else lua_assert(gnext(f) == 0);
gnext(mp) = cast_int(f - mp);
mp = f;
}
}
setnodekey(L, mp, key);
luaC_barrierback(L, obj2gco(t), key);
lua_assert(isempty(gval(mp)));
return gval(mp);
}
- 分配新位置的流程为:
- 检查传入的 key 是否为 nil ,为 nil 则抛异常。
- 如果 key 是 float 类型,则尝试转换成 int 类型。
- 根据 key 的类型和值进行 hash 计算,根据计算结果查找存放的主节点位置。
- 如果存放的主节点位置不为空(即已经存放了数据),或当前哈希表没有空闲位置,则需要进一步分配位置。
- 如果当前哈希表已经没有空闲位置,就调用 rehash 方法,对哈希表进行扩容,再为 key 分配位置返回。
- 如果当前哈希表还有空闲位置,但是当前主节点位置不为空,则根据该节点的 key 类型和值,计算其应该分配的位置,是否和主节点相同。
- 如果主节点的节点信息计算出来的位置节点,和主节点相同,即两个节点的 key 具有相同的 hash 计算结果,则把空闲节点指向主节点的下一个节点,再把主节点指向空闲节点,形成的链表顺序为:主节点 -> 最后一次分配的节点 -> 倒数第二次分配的节点 -> ….
- 如果主节点的节点信息计算出来的位置节点,和主节点不同,即两个节点的 key 的 hash 计算结果不一致,归属于两个链表,因此需要将主节点的数据转到空闲节点中,再链接到其对应的链表,将主节点作为新的 key 的存放节点。
- 将 key 设置到分配的节点中,并返回节点位置。
读取 table
- 读取 table 中的值,通过 lua_gettable 方法实现。
// lapi.c
LUA_API int lua_gettable (lua_State *L, int idx) {
const TValue *slot;
TValue *t;
lua_lock(L);
t = index2value(L, idx);
if (luaV_fastget(L, t, s2v(L->top - 1), slot, luaH_get)) {
setobj2s(L, L->top - 1, slot);
}
else
luaV_finishget(L, t, s2v(L->top - 1), L->top - 1, slot);
lua_unlock(L);
return ttype(s2v(L->top - 1));
}
- 和 lua_settable 一样,先获取当前 table 中是否有对应的 key 值。如果找到对应 key ,则调用 luaV_finishget 继续查找。
// lvm.c
void luaV_finishget (lua_State *L, const TValue *t, TValue *key, StkId val,
const TValue *slot) {
int loop; /* counter to avoid infinite loops */
const TValue *tm; /* metamethod */
for (loop = 0; loop < MAXTAGLOOP; loop++) {
if (slot == NULL) { /* 't' is not a table? */
lua_assert(!ttistable(t));
tm = luaT_gettmbyobj(L, t, TM_INDEX);
if (unlikely(notm(tm)))
luaG_typeerror(L, t, "index"); /* no metamethod */
/* else will try the metamethod */
}
else { /* 't' is a table */
lua_assert(isempty(slot));
tm = fasttm(L, hvalue(t)->metatable, TM_INDEX); /* table's metamethod */
if (tm == NULL) { /* no metamethod? */
setnilvalue(s2v(val)); /* result is nil */
return;
}
/* else will try the metamethod */
}
if (ttisfunction(tm)) { /* is metamethod a function? */
luaT_callTMres(L, tm, t, key, val); /* call it */
return;
}
t = tm; /* else try to access 'tm[key]' */
if (luaV_fastget(L, t, key, slot, luaH_get)) { /* fast track? */
setobj2s(L, val, slot); /* done */
return;
}
/* else repeat (tail call 'luaV_finishget') */
}
luaG_runerror(L, "'__index' chain too long; possible loop");
}
- 和 luaV_finishset 流程相似,luaV_finishget 也会根据是否有元表,会进行不同处理。
- 当前 table 没有元表,或者元表没有 __index ,则当前 table 不存在对应 key ,返回 nil 。
- 当前 table 元表 __index 为方法,调用 __index 方法查找后返回结果。
- 当前 table 元表 __index 不为方法,则在 __index 中进行查找。
- 如果找到 key ,则将对应结果返回。
- 如果找不到 key ,则将 __index 传入 luaV_finishget ,递归调用,返回结果(调用上限为 2000 次)。
设置 table 尺寸
- 调用 lua_createtable 创建 table 时,如果传入了数组长度和哈希表长度,就会调用 luaH_resize 方法进行尺寸设置。
// ltable.c
void luaH_resize (lua_State *L, Table *t, unsigned int newasize,
unsigned int nhsize) {
unsigned int i;
Table newt; /* to keep the new hash part */
unsigned int oldasize = setlimittosize(t);
TValue *newarray;
/* create new hash part with appropriate size into 'newt' */
setnodevector(L, &newt, nhsize);
if (newasize < oldasize) { /* will array shrink? */
t->alimit = newasize; /* pretend array has new size... */
exchangehashpart(t, &newt); /* and new hash */
/* re-insert into the new hash the elements from vanishing slice */
for (i = newasize; i < oldasize; i++) {
if (!isempty(&t->array[i]))
luaH_setint(L, t, i + 1, &t->array[i]);
}
t->alimit = oldasize; /* restore current size... */
exchangehashpart(t, &newt); /* and hash (in case of errors) */
}
/* allocate new array */
newarray = luaM_reallocvector(L, t->array, oldasize, newasize, TValue);
if (unlikely(newarray == NULL && newasize > 0)) { /* allocation failed? */
freehash(L, &newt); /* release new hash part */
luaM_error(L); /* raise error (with array unchanged) */
}
/* allocation ok; initialize new part of the array */
exchangehashpart(t, &newt); /* 't' has the new hash ('newt' has the old) */
t->array = newarray; /* set new array part */
t->alimit = newasize;
for (i = oldasize; i < newasize; i++) /* clear new slice of the array */
setempty(&t->array[i]);
/* re-insert elements from old hash part into new parts */
reinsert(L, &newt, t); /* 'newt' now has the old hash */
freehash(L, &newt); /* free old hash part */
}
- table 设置尺寸的流程为:
- 记录旧的数组长度。
- 根据新的哈希表长度,创建一个临时哈希表。
- 如果新的数组长度比旧的小,即要缩小数组大小,则:
- 设置 table 的数组上限长度为新的长度。
- 将 table 原本的哈希表数据和临时哈希表数据交换,即将 table 的哈希表数据设置为临时的哈希表数据。
- 将数组部分超出上限的部分设置到临时哈希表中。
- 恢复 table 的数组上限长度为旧的长度。
- 将 table 的哈希表数据设置为原本的哈希表数据,数组部分额外的数据则保存在临时哈希表中。
- 根据新的数组长度创建新的数组对象。
- 将 table 的哈希表数据设置为临时哈希表数据,即保持哈希表优先设置数组的数据。
- 更新 table 的数组和数组上限长度。
- 将原本的哈希表数据重新插入到 table 中。
- 释放临时哈希表。
- 从前面读写的流程可以知道,table 的数组部分并不代表所有的数组数据,超出数组上限的部分会存放到哈希表中。因此,当哈希表没法再插入新的值时,需要调用 rehash 方法,计算需要扩容的尺寸。
// ltable.c
static void rehash (lua_State *L, Table *t, const TValue *ek) {
unsigned int asize; /* optimal size for array part */
unsigned int na; /* number of keys in the array part */
unsigned int nums[MAXABITS + 1];
int i;
int totaluse;
for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */
setlimittosize(t);
na = numusearray(t, nums); /* count keys in array part */
totaluse = na; /* all those keys are integer keys */
totaluse += numusehash(t, nums, &na); /* count keys in hash part */
/* count extra key */
if (ttisinteger(ek))
na += countint(ivalue(ek), nums);
totaluse++;
/* compute new size for array part */
asize = computesizes(nums, &na);
/* resize the table to new computed sizes */
luaH_resize(L, t, asize, totaluse - na);
}
- 为了确定扩容后需要的大小,对数组部分和哈希表部分进行统计。除了计算当前使用的所有位置数量,还要统计所有类型为 int 的 key,在 (2 ^ (i - 1), 2 ^ i] 区间的数量分布。key 类型为 int ,都认为 key 值为数组索引,优先选择存入数组部分,查找效率会比较高。统计完成后,通过调用 computesizes 方法,来确定最终的尺寸大小。
// ltable.c
static unsigned int computesizes (unsigned int nums[], unsigned int *pna) {
int i;
unsigned int twotoi; /* 2^i (candidate for optimal size) */
unsigned int a = 0; /* number of elements smaller than 2^i */
unsigned int na = 0; /* number of elements to go to array part */
unsigned int optimal = 0; /* optimal size for array part */
/* loop while keys can fill more than half of total size */
for (i = 0, twotoi = 1;
twotoi > 0 && *pna > twotoi / 2;
i++, twotoi *= 2) {
a += nums[i];
if (a > twotoi/2) { /* more than half elements present? */
optimal = twotoi; /* optimal size (till now) */
na = a; /* all elements up to 'optimal' will go to array part */
}
}
lua_assert((optimal == 0 || optimal / 2 < na) && na <= optimal);
*pna = na;
return optimal;
}
- 当 key 值在区间 [0, 2 ^ i] 的数量超过 2 ^ (i - 1) 时,就会使用 2 ^ i 作为数组的尺寸大小。也就是说,存入数组部分的数量,必须达到数组长度的 1/2 ,该数组长度才是合适的。因此,数组大小只会取能满足条件的区间部分对应的长度,不在区间内的,则全部存入到哈希表中,哈希表的长度,也就等于总数量减去存入数组部分的数量。
- 可以看到,对数组部分的长度要求,可以保证数组部分使用率达到 50% 以上,同时,哈希表会在没有空闲位置时,才会进行扩容,而每一次数组扩容时,也会重新计算存入哈希表的数量,因此哈希表的使用率同样是保持 50% 以上。
示例
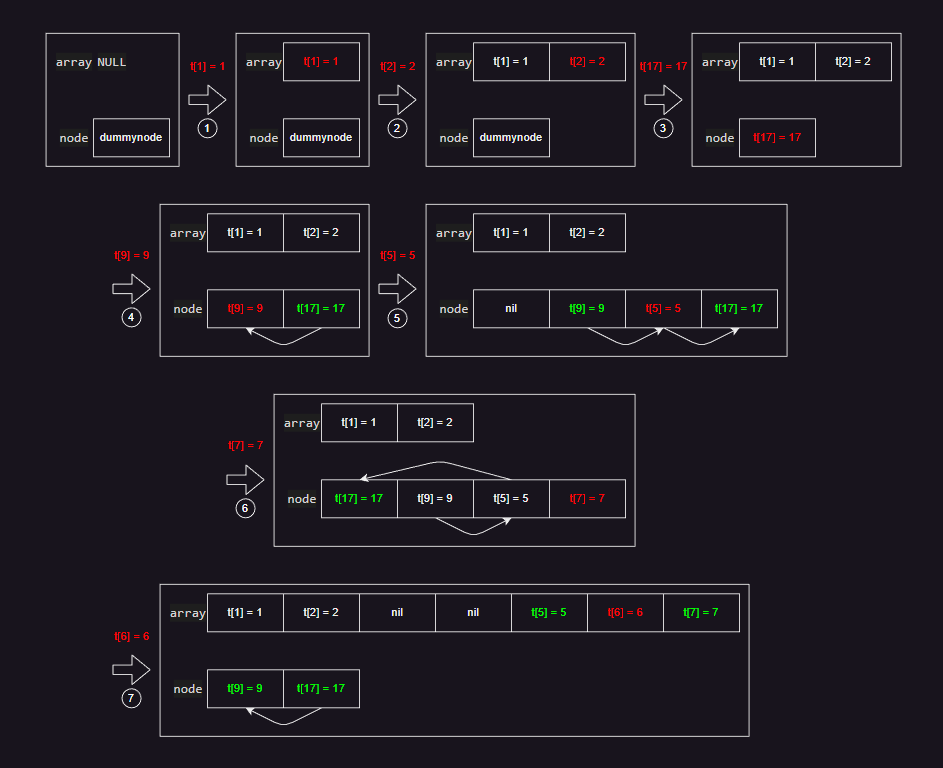
- 以 int 类型为例,一个 table 的存入过程如上图所示(红色为新加入的 key ,绿色为发生变动的 key):
-
- 对一个新建的 table ,设置 t[1] = 1 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 1 处于区间 [0, 2 ^ 0] ,数量为 1 ,大于 2 ^ (0 - 1) ,因此扩大数组长度为 1 。
- 将 t[1] 存入数组部分 array[0]。
-
- 设置 t[2] = 2 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 2 处于区间 [0, 2 ^ 1] ,数量为 2 ,大于 2 ^ (1 - 1) ,因此扩大数组长度为 2 。
- 将 t[2] 存入数组部分 array[1]。
-
- 设置 t[17] = 17 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 17 处于区间 [0, 2 ^ 5] ,数量为 3 ,小于 2 ^ (5 - 1) ,因此扩大哈希表长度为 1 。
- 将 t[17] 存入哈希表 node[0]。
-
- 设置 t[9] = 9 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 9 处于区间 [0, 2 ^ 4] ,数量为 3 ,小于 2 ^ (4 - 1) ,因此扩大哈希表长度为 2 。
- 原 node[0] 的 t[17] 的 key 值重新进行 hash 计算,结果为 1 ,因此 t[17] 存入 node[1]。
- t[9] 的 key 值 hash 计算结果同样为 1 ,由于 node[1] 已经写入了数据,其 key 不相同,所以不能覆盖。
- 由于 node[1] 的 key 值做 hash 计算还是为 1 ,即 node[1] 的数据和当前节点符合,是主节点。
- 从后往前在 node 中查找空闲节点,找到 node[0] ,将 t[9] 存入 node[0] 中。
- 设置 node 的链表指向,从 node[1] 指向 node[0] 。
-
- 设置 t[5] = 5 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 5 处于区间 [0, 2 ^ 3] ,数量为 3 ,小于 2 ^ (3 - 1) ,因此扩大哈希表长度为 4 。
- 原 node[0] 的 t[9] 的 key 值重新进行 hash 计算,结果为 1 ,因此 t[9] 存入 node[1] 。
- 原 node[1] 的 t[17] 的 key 值 hash 计算结果同样为 1 ,与第 4 步同理,因此 t[17] 存入 node[3] ,node[1] 指向 node[3] 。
- t[5] 的 key 值 hash 计算结果也为 1 ,下一个空闲节点为 node[2] ,将 node[2] 指向 node[1] 的下一个节点,即 node[2] 指向 node[3] 。
- t[5] 设置到到 node[2] 中,将主节点 node[1] 指向 node[2] ,而 node[2] 指向 node[3] ,链表中的元素数量增加。
-
- 设置 t[7] = 7 ,由于数组没有可存入位置,哈希表有空闲位置,所以不需要进行扩容。
- t[7] 的 key 值 hash 计算结果为 3 ,由于 node[3] 已经写入了数据,其 key 不相同,所以不能覆盖。
- 由于 node[3] 的 key = 17 ,做 hash 计算为 1 ,和当前节点不符合,因此找到下一个空闲节点 node[0] 。
- 找到 node[3] 的主节点 node[1] ,遍历链表,找到 node[3] 的上一个节点 node[2] 。
- 将 node[2] 指向 node[0] ,将 node[3] 的数据 t[17] 存入 node[0] 中。
- 将 t[7] 存入 node[3] 中。
-
- 设置 t[6] = 6 ,由于数组和哈希表都没有可存入位置,需要进行扩容。
- 由于 key = 6 处于区间 [0, 2 ^ 3] ,数量为 5 ,大于 2 ^ (3 - 1) ,因此扩大数组长度为 8 ,同时哈希表长度缩短为 2 。
- 原 node[2] 和 node[3] 的 key 值小于数组长度,直接存入数组 array[4] 、array[6] 中。
- 原 node[0] 和 node[1] 重新存入 node 中,node[1] 指向 node[0] 。
- t[6] 直接存入数组部分 array[5] 中。
-
获取 table 长度
- 在 lua 中获取 table 长度,通常使用 #t 返回。从 ‘#’ 转变成获取长度的过程主要代码如下:
// lparse.c
static UnOpr getunopr (int op) {
switch (op) {
case TK_NOT: return OPR_NOT;
case '-': return OPR_MINUS;
case '~': return OPR_BNOT;
case '#': return OPR_LEN;
default: return OPR_NOUNOPR;
}
}
// lcode.h
typedef enum UnOpr { OPR_MINUS, OPR_BNOT, OPR_NOT, OPR_LEN, OPR_NOUNOPR } UnOpr;
// lcode.c
void luaK_prefix (FuncState *fs, UnOpr op, expdesc *e, int line) {
static const expdesc ef = {VKINT, {0}, NO_JUMP, NO_JUMP};
luaK_dischargevars(fs, e);
switch (op) {
case OPR_MINUS: case OPR_BNOT: /* use 'ef' as fake 2nd operand */
if (constfolding(fs, op + LUA_OPUNM, e, &ef))
break;
/* else */ /* FALLTHROUGH */
case OPR_LEN:
codeunexpval(fs, cast(OpCode, op + OP_UNM), e, line);
break;
case OPR_NOT: codenot(fs, e); break;
default: lua_assert(0);
}
}
// loprcodes.h
typedef enum {
/*----------------------------------------------------------------------
name args description
------------------------------------------------------------------------*/
...
OP_UNM,/* A B R[A] := -R[B] */
OP_BNOT,/* A B R[A] := ~R[B] */
OP_NOT,/* A B R[A] := not R[B] */
OP_LEN,/* A B R[A] := length of R[B] */
...
} OpCode;
// lvm.c
void luaV_execute (lua_State *L, CallInfo *ci) {
LClosure *cl;
TValue *k;
StkId base;
const Instruction *pc;
int trap;
#if LUA_USE_JUMPTABLE
#include "ljumptab.h"
#endif
tailcall:
trap = L->hookmask;
cl = clLvalue(s2v(ci->func));
k = cl->p->k;
pc = ci->u.l.savedpc;
if (trap) {
if (cl->p->is_vararg)
trap = 0; /* hooks will start after VARARGPREP instruction */
else if (pc == cl->p->code) /* first instruction (not resuming)? */
luaD_hookcall(L, ci);
ci->u.l.trap = 1; /* there may be other hooks */
}
base = ci->func + 1;
/* main loop of interpreter */
for (;;) {
Instruction i; /* instruction being executed */
StkId ra; /* instruction's A register */
vmfetch();
lua_assert(base == ci->func + 1);
lua_assert(base <= L->top && L->top < L->stack + L->stacksize);
/* invalidate top for instructions not expecting it */
lua_assert(isIT(i) || (cast_void(L->top = base), 1));
vmdispatch (GET_OPCODE(i)) {
...
vmcase(OP_LEN) {
Protect(luaV_objlen(L, ra, vRB(i)));
vmbreak;
}
...
}
}
- 可以看到,'#' 符号首先转换成 UnOpr.OPR_LEN 类型,再转换成 OpCode.OP_LEN 类型,最后根据 OpCode 类型,调用 luaV_objlen 方法获取长度。
// lvm.c
void luaV_objlen (lua_State *L, StkId ra, const TValue *rb) {
const TValue *tm;
switch (ttypetag(rb)) {
case LUA_VTABLE: {
Table *h = hvalue(rb);
tm = fasttm(L, h->metatable, TM_LEN);
if (tm) break; /* metamethod? break switch to call it */
setivalue(s2v(ra), luaH_getn(h)); /* else primitive len */
return;
}
case LUA_VSHRSTR: {
setivalue(s2v(ra), tsvalue(rb)->shrlen);
return;
}
case LUA_VLNGSTR: {
setivalue(s2v(ra), tsvalue(rb)->u.lnglen);
return;
}
default: { /* try metamethod */
tm = luaT_gettmbyobj(L, rb, TM_LEN);
if (unlikely(notm(tm))) /* no metamethod? */
luaG_typeerror(L, rb, "get length of");
break;
}
}
luaT_callTMres(L, tm, rb, rb, ra);
}
- 对 table 类型,先检查其元表是否有 __len 方法,如果有,则调用该元方法返回 table 长度。如果没有,则需要通过 luaH_getn 方法来获取。
// ltable.c
lua_Unsigned luaH_getn (Table *t) {
unsigned int limit = t->alimit;
if (limit > 0 && isempty(&t->array[limit - 1])) { /* (1)? */
/* there must be a boundary before 'limit' */
if (limit >= 2 && !isempty(&t->array[limit - 2])) {
/* 'limit - 1' is a boundary; can it be a new limit? */
if (ispow2realasize(t) && !ispow2(limit - 1)) {
t->alimit = limit - 1;
setnorealasize(t); /* now 'alimit' is not the real size */
}
return limit - 1;
}
else { /* must search for a boundary in [0, limit] */
unsigned int boundary = binsearch(t->array, 0, limit);
/* can this boundary represent the real size of the array? */
if (ispow2realasize(t) && boundary > luaH_realasize(t) / 2) {
t->alimit = boundary; /* use it as the new limit */
setnorealasize(t);
}
return boundary;
}
}
/* 'limit' is zero or present in table */
if (!limitequalsasize(t)) { /* (2)? */
/* 'limit' > 0 and array has more elements after 'limit' */
if (isempty(&t->array[limit])) /* 'limit + 1' is empty? */
return limit; /* this is the boundary */
/* else, try last element in the array */
limit = luaH_realasize(t);
if (isempty(&t->array[limit - 1])) { /* empty? */
/* there must be a boundary in the array after old limit,
and it must be a valid new limit */
unsigned int boundary = binsearch(t->array, t->alimit, limit);
t->alimit = boundary;
return boundary;
}
/* else, new limit is present in the table; check the hash part */
}
/* (3) 'limit' is the last element and either is zero or present in table */
lua_assert(limit == luaH_realasize(t) &&
(limit == 0 || !isempty(&t->array[limit - 1])));
if (isdummy(t) || isempty(luaH_getint(t, cast(lua_Integer, limit + 1))))
return limit; /* 'limit + 1' is absent */
else /* 'limit + 1' is also present */
return hash_search(t, limit);
}
- 检查 table 长度的流程为:
- alimit 大于 0 ,并且 array[alimit - 1] 为空。
- 如果 array[alimit - 2] 不为空,则 table 长度为 alimit - 1 。
- 确定 table 长度后,如果 alimit 不为 array 真实长度(table 的 flags 的第 8 位为 1)或 alimit 是 2 的指数次幂,并且新的长度(alimit - 1)不为 2 的指数次幂,则设置 alimit 为新的长度,并且标记 table 的alimit 为非 array 真实长度。
- 如果 array[alimit - 2] 为空,则进行二分查找,当 array[i] 为空,且 array[i - 1] 不为空时,i 即为 table 长度。
- 确定 table 长度后,如果 alimit 不为 array 真实长度(table 的 flags 的第 8 位为 1)或 alimit 是 2 的指数次幂,并且新的长度大于 array 真实长度的一半时,设置 alimit 为新的长度,并且标记 table 的alimit 为非 array 真实长度。
- 如果 array[alimit - 2] 不为空,则 table 长度为 alimit - 1 。
- alimit 为 0 或 array[alimit - 1] 不为空。
- alimit 不是 array 的真实长度,并且 alimit 不是 2 的指数次幂。
- array[alimit] 为空,则 table的长度为 alimit 。
- array[alimit] 不为空。
- array[array.length - 1] 为空,即 alimit 是旧的 table 长度,目前的 table 的长度处在 (alimit, array.length) 区间,使用二分查找得到 table 长度。
- 将 alimit 更新为新的长度。
- array[array.length - 1] 不为空。
- 哈希表为空,或者哈希表不存在 array.length + 1 的 key,则 table 的长度为 array.length 。
- 哈希表存在 array.length + 1 的 key ,则在哈希表中查找长度。
- 确定 table 的长度所处区间(i, j)。
- 设置 i = array.length ,j = array.length * 2 ,检查哈希表中是否存在 key 为 j 的节点。
- 如果存在对应节点,则更新区间,i = j ,j = j * 2 ,继续查找,直到不存在对应节点或者 j 大于 2 ^ 30 。
- 在区间(i, j)内,使用二分查找得到 table 的长度。
- 确定 table 的长度所处区间(i, j)。
- array[array.length - 1] 为空,即 alimit 是旧的 table 长度,目前的 table 的长度处在 (alimit, array.length) 区间,使用二分查找得到 table 长度。
- alimit 是 array 的真实长度或 alimit 是 2 的指数次幂。
- 哈希表为空,或者哈希表不存在 array.length + 1 的 key,则 table 的长度为 array.length 。
- 哈希表存在 array.length + 1 的 key ,则在哈希表中查找长度。
- alimit 不是 array 的真实长度,并且 alimit 不是 2 的指数次幂。
- alimit 大于 0 ,并且 array[alimit - 1] 为空。
- 可以看到,检查的流程有点复杂,其中有几个主要的点:
- table 长度,是以 t[i] 存在且 t[i + 1] 不存在作为主要判断条件,即连续的常规数组能获取到正确的长度,而非连续的数组、键值对等情况则不能保证。
- 只有数组部分的最后一个索引都有值时,才会去哈希表中继续查找,不然 table 的长度只会在 [0, array.length] 范围内。
- 通常情况下,alimit 代表数组部分长度。获取 table 长度时,当 table 长度小于数组部分长度时,会修改 alimit 的值为 table 的当前长度,则下次获取长度时能快速返回,不需要每次都进行二分查找。
- 修改 alimit 的值时,会限制在 (array.length / 2, array.length] 范围,因为 alimit 主要用于获取数组部分长度。因此,如果 table 的长度在 [0, array.length / 2] 内时,则每次都还是需要进行二分查找。也就是说,只有当数组部分的使用率在 50% 以上时,频繁获取 table 的长度才不会有额外的计算。
获取 table 的下一个值
- 在 lua 中,通过 next 方法,可以获取 table 的下一个值,主要的代码实现为:
// ltable.c
int luaH_next (lua_State *L, Table *t, StkId key) {
unsigned int asize = luaH_realasize(t);
unsigned int i = findindex(L, t, s2v(key), asize); /* find original key */
for (; i < asize; i++) { /* try first array part */
if (!isempty(&t->array[i])) { /* a non-empty entry? */
setivalue(s2v(key), i + 1);
setobj2s(L, key + 1, &t->array[i]);
return 1;
}
}
for (i -= asize; cast_int(i) < sizenode(t); i++) { /* hash part */
if (!isempty(gval(gnode(t, i)))) { /* a non-empty entry? */
Node *n = gnode(t, i);
getnodekey(L, s2v(key), n);
setobj2s(L, key + 1, gval(n));
return 1;
}
}
return 0; /* no more elements */
}
static unsigned int findindex (lua_State *L, Table *t, TValue *key,
unsigned int asize) {
unsigned int i;
if (ttisnil(key)) return 0; /* first iteration */
i = ttisinteger(key) ? arrayindex(ivalue(key)) : 0;
if (i - 1u < asize) /* is 'key' inside array part? */
return i; /* yes; that's the index */
else {
const TValue *n = getgeneric(t, key);
if (unlikely(isabstkey(n)))
luaG_runerror(L, "invalid key to 'next'"); /* key not found */
i = cast_int(nodefromval(n) - gnode(t, 0)); /* key index in hash table */
/* hash elements are numbered after array ones */
return (i + 1) + asize;
}
}
static const TValue *getgeneric (Table *t, const TValue *key) {
Node *n = mainpositionTV(t, key);
for (;;) { /* check whether 'key' is somewhere in the chain */
if (equalkey(key, n))
return gval(n); /* that's it */
else {
int nx = gnext(n);
if (nx == 0)
return &absentkey; /* not found */
n += nx;
}
}
}
- 通过 findindex 方法,查找指定的 key 值对应的下一个索引位置。
- 如果 key 为 nil ,则从数组部分开始查找,下一个索引位置为 0 。
- 如果 key - 1 小于数组长度,则 key 对应的值仍处于数组部分,下一个索引位置 key 。
- 如果 key 大于数组长度,则 key 对应的值处于哈希表部分,找到存入的位置节点,下一个索引位置即为该节点在 node 中的索引值加 1,再加上数组的长度。
- 根据得到的索引值,获取该位置对应的值,如果对应的值为空,则会返回 nil 。
迭代器访问 table
- 迭代器访问 table ,即 for 遍历,代码结构如下:
for val_1, val_2, ... , val_n in explist do
block
end
- 上述代码等价于
do
local func, state, val = explist
while true do
local val_1, val_2, ... , val_n = func(state, val)
if val_1 == nil then
break
end
val = val_1
block
end
- 其中,explist 为迭代器,只执行一次,返回迭代器函数 func 、状态 state 、迭代器初始值 val 。遍历过程即执行 func ,将返回的第一个参数 val_1 作为新的 val ,执行完 block 代码块后,再继续执行 func ,直到返回的第一个参数为空时停止。
- table 的迭代器有两种,pairs 和 ipairs 。
pairs
- pairs 方法的代码如下:
// lbaselib.c
static int luaB_pairs (lua_State *L) {
luaL_checkany(L, 1);
if (luaL_getmetafield(L, 1, "__pairs") == LUA_TNIL) { /* no metamethod? */
lua_pushcfunction(L, luaB_next); /* will return generator, */
lua_pushvalue(L, 1); /* state, */
lua_pushnil(L); /* and initial value */
}
else {
lua_pushvalue(L, 1); /* argument 'self' to metamethod */
lua_call(L, 1, 3); /* get 3 values from metamethod */
}
return 3;
}
- 根据是否有元方法,pairs 会执行不同的流程。
- 如果当前 table 没有元表,或元表没有元方法 __pairs ,则迭代器函数为 luaB_next ,状态为 table ,初始值为 nil ,即使用 next 方法来完成迭代访问过程。
- 如果当前 table 有元表,并且有元方法 __pairs ,则将 table 作为参数,调用 __pairs 方法,并返回三个参数,对应迭代器函数、状态、初始值,从而完成迭代过程。
- __pairs 的方法大致为:
__pairs = function(table)
local func = function(table, key)
local nextKey = findNextKey()
local nextValue = table[nextKey]
return nextKey, nextValue
end
return func, table, nil
end
- 没有 __pairs 方法时,则使用 luaB_next 返回,其实现为:
// lbaselib.c
static int luaB_next (lua_State *L) {
luaL_checktype(L, 1, LUA_TTABLE);
lua_settop(L, 2); /* create a 2nd argument if there isn't one */
if (lua_next(L, 1))
return 2;
else {
lua_pushnil(L);
return 1;
}
}
// lapi.c
LUA_API int lua_next (lua_State *L, int idx) {
Table *t;
int more;
lua_lock(L);
api_checknelems(L, 1);
t = gettable(L, idx);
more = luaH_next(L, t, L->top - 1);
if (more) {
api_incr_top(L);
}
else /* no more elements */
L->top -= 1; /* remove key */
lua_unlock(L);
return more;
}
// ltable.c
int luaH_next (lua_State *L, Table *t, StkId key) {
unsigned int asize = luaH_realasize(t);
unsigned int i = findindex(L, t, s2v(key), asize); /* find original key */
for (; i < asize; i++) { /* try first array part */
if (!isempty(&t->array[i])) { /* a non-empty entry? */
setivalue(s2v(key), i + 1);
setobj2s(L, key + 1, &t->array[i]);
return 1;
}
}
for (i -= asize; cast_int(i) < sizenode(t); i++) { /* hash part */
if (!isempty(gval(gnode(t, i)))) { /* a non-empty entry? */
Node *n = gnode(t, i);
getnodekey(L, s2v(key), n);
setobj2s(L, key + 1, gval(n));
return 1;
}
}
return 0; /* no more elements */
}
static unsigned int findindex (lua_State *L, Table *t, TValue *key,
unsigned int asize) {
unsigned int i;
if (ttisnil(key)) return 0; /* first iteration */
i = ttisinteger(key) ? arrayindex(ivalue(key)) : 0;
if (i - 1u < asize) /* is 'key' inside array part? */
return i; /* yes; that's the index */
else {
const TValue *n = getgeneric(t, key);
if (unlikely(isabstkey(n)))
luaG_runerror(L, "invalid key to 'next'"); /* key not found */
i = cast_int(nodefromval(n) - gnode(t, 0)); /* key index in hash table */
/* hash elements are numbered after array ones */
return (i + 1) + asize;
}
}
ipairs
- ipairs 方法的代码如下:
// lbaselib.c
static int luaB_ipairs (lua_State *L) {
luaL_checkany(L, 1);
lua_pushcfunction(L, ipairsaux); /* iteration function */
lua_pushvalue(L, 1); /* state */
lua_pushinteger(L, 0); /* initial value */
return 3;
}
- ipairs 的迭代器方法为 ipairsaux ,其代码为:
// lbaselib.c
static int ipairsaux (lua_State *L) {
lua_Integer i = luaL_checkinteger(L, 2) + 1;
lua_pushinteger(L, i);
return (lua_geti(L, 1, i) == LUA_TNIL) ? 1 : 2;
}
- 迭代器的初始值为 0 ,迭代器函数会对传入的参数加 1 ,再获取 table 中的值并压入栈上。当 table 中存在对应 key 时,ipairs 会返回栈顶的两个值,即 key-value ,而当 table 中不存在对应 key 时,则只会返回一个值,即存放在栈顶的 value ,此时 value 为 nil 。因此,迭代器函数的返回值 val_1 即为 nil ,遍历停止。
- 和 pairs 相比,ipairs 只能遍历 key 值为从 1 开始的连续范围,当某一个 key 值不存在时,则会中断,即只能遍历常规数组类型的 table 。
总结
- table 是 lua 中重要的数据结构,同时具备数组和哈希表的功能,但却不是简单的数组部分对应数组存储,哈希表部分对应哈希表存储,基于内存优化做了一系列的处理。了解其中的实现细节,有助于更好地使用这种类型。