垃圾回收(GC)是程序运行中必不可少的一环,lua 内部则实现了一套垃圾回收流程。
简介
- 在游戏项目中,lua 的主要优势,在于能进行热更新,能及时修复线上运行过程中出现的问题,尽可能地缩短流程时长。另一方面,对于开发者来讲,lua 的另一个优势,即其内部实现了一套垃圾回收流程,可以自动进行垃圾回收,不需要开发者进行主动管理,为开发者提供了较大的便利。
- 尽管 lua 有垃圾回收机制,但如果不了解其内部实现,就不知道需要注意的地方。为了做好内存管理,还是需要进一步了解掌握 lua 的垃圾回收机制。
初始化
- lua 初始化的方法如下:
// lstate.c
LUA_API lua_State *lua_newstate (lua_Alloc f, void *ud) {
int i;
lua_State *L;
global_State *g;
LG *l = cast(LG *, (*f)(ud, NULL, LUA_TTHREAD, sizeof(LG)));
if (l == NULL) return NULL;
L = &l->l.l;
g = &l->g;
L->tt = LUA_VTHREAD;
g->currentwhite = bitmask(WHITE0BIT);
L->marked = luaC_white(g);
preinit_thread(L, g);
g->allgc = obj2gco(L); /* by now, only object is the main thread */
L->next = NULL;
g->Cstacklimit = L->nCcalls = LUAI_MAXCSTACK + CSTACKERR;
incnny(L); /* main thread is always non yieldable */
g->frealloc = f;
g->ud = ud;
g->warnf = NULL;
g->ud_warn = NULL;
g->mainthread = L;
g->seed = luai_makeseed(L);
g->gcrunning = 0; /* no GC while building state */
g->strt.size = g->strt.nuse = 0;
g->strt.hash = NULL;
setnilvalue(&g->l_registry);
g->panic = NULL;
g->gcstate = GCSpause;
g->gckind = KGC_INC;
g->gcemergency = 0;
g->finobj = g->tobefnz = g->fixedgc = NULL;
g->firstold1 = g->survival = g->old1 = g->reallyold = NULL;
g->finobjsur = g->finobjold1 = g->finobjrold = NULL;
g->sweepgc = NULL;
g->gray = g->grayagain = NULL;
g->weak = g->ephemeron = g->allweak = NULL;
g->twups = NULL;
g->totalbytes = sizeof(LG);
g->GCdebt = 0;
g->lastatomic = 0;
setivalue(&g->nilvalue, 0); /* to signal that state is not yet built */
setgcparam(g->gcpause, LUAI_GCPAUSE);
setgcparam(g->gcstepmul, LUAI_GCMUL);
g->gcstepsize = LUAI_GCSTEPSIZE;
setgcparam(g->genmajormul, LUAI_GENMAJORMUL);
g->genminormul = LUAI_GENMINORMUL;
for (i=0; i < LUA_NUMTAGS; i++) g->mt[i] = NULL;
if (luaD_rawrunprotected(L, f_luaopen, NULL) != LUA_OK) {
/* memory allocation error: free partial state */
close_state(L);
L = NULL;
}
return L;
}
- 其中,gc 相关的参数也进行了初始化状态,主要参数有:
- currentwhite
- 当前 gc 过程的白色类型,包括 WHITE0BIT 、WHITE1BIT ,通过两种类型交替使用,来表示对象是上一轮还是当前轮 gc 处理的对象。
- allgc
- 所有需要 gc 的对象链表。
- gcstate
- 当前 gc 过程所处的状态,有以下状态:
- GCSpropagate :扫描标记状态。
- GCSenteratomic :准备进入原子处理的状态。
- GCSatomic :原子处理状态。
- GCSswpallgc :清除 allgc 列表状态。
- GCSswpfinobj :清除 finobj 列表状态。
- GCSswptobefnz :清除 tobefnz 列表状态。
- GCSswpend :清除完成状态。
- GCScallfin :执行析构方法状态。
- GCSpause :暂停状态(初始化时的默认状态)。
- 当前 gc 过程所处的状态,有以下状态:
- gckind
- gc 类型,有两种类型:
- KGC_INC :增量式 gc(初始化时的默认状态)。
- KGC_GEN :分代式 gc 。
- gc 类型,有两种类型:
- gcemergency
- 紧急 gc 标记,如果不为 0 ,则会跳过一些操作,避免某些操作(如执行析构方法、缩小数据结构等)在非预期的情况下,更改解释器状态。
- finobj
- 带析构方法的对象列表。
- tobefnz
- 将要执行析构方法的对象列表。
- sweepgc
- 当前清除对象列表。
- gray
- 灰色对象列表(用于记录当前灰色对象,和对象的 gclist 组合使用)。
- grayagain
- 需要进行原子处理遍历的对象列表。
- weak
- 弱值(value)类型 table 列表。
- ephemeron
- 弱键(key)类型 table 列表。
- allweak
- 弱键值(key-value)类型 table 列表。
- GCdebt
- 已经申请且还没被收集器补偿的内存字节数,用于管理 gc 启动的时机,当大于 0 时才会开启 gc 。创建新对象时增加,释放时减少。
- totalbytes
- 已经申请且被收集器补偿的内存字节数,和 GCdebt 相加表示未释放的总内存。
- gcpause
- 下一轮 gc 开启时内存需要达到的倍数 * 100 ,默认为 200(LUAI_GCPAUSE)。
- gcstepsize
- 每一步处理的大小,以 2 为底的对数表示,默认为 13(LUAI_GCSTEPSIZE),即 8 KB 。
- gcstepmul
- 每一步处理的大小的放大倍数,可近似为每单位新增内存需要 gc 处理的内存大小,默认为 100(LUAI_GCMUL)。
- GCestimate
- 使用中的内存估计大小,通常为当前未释放的总内存大小,和 gettotalbytes(g) 的值一致。
- currentwhite
- 所有需要 gc 的对象,最终都通过 luaC_newobj 方法创建。
// lgc.c
GCObject *luaC_newobj (lua_State *L, int tt, size_t sz) {
global_State *g = G(L);
GCObject *o = cast(GCObject *, luaM_newobject(L, novariant(tt), sz));
o->marked = luaC_white(g);
o->tt = tt;
o->next = g->allgc;
g->allgc = o;
return o;
}
- 创建一个新对象,会将其标记为当前的白色,并且会将该对象设置到 g->allgc 列表上,用于后续 gc 处理时进行遍历。
算法流程
- 标记清除算法的主要流程为:
- 所有对象创建的时候标记为白色。
- gc 开始后,遍历检查所有对象,如果还有引用的,就标记为黑色。
- 标记完成后,所有标记为白色的对象,表示对象没有引用,直接清除。
- 清除完成后,将所有黑色的对象重新标记为白色,等待下一次 gc 。
- 由于需要检查完所有对象进行标记,再对所有对象进行处理,执行一次 gc 的耗时相对较长。因此,lua 的 gc 加入了分步的概念,每次处理都有上限数量,将整个过程切分成多个小步骤循环执行,主要流程为:
- 设置当前白色为白色 1 ,所有对象创建的时候标记为白色 1 。
- gc 开始后,遍历检查所有对象,如果还有引用的,就标记为灰色,加入灰色列表。
- 取出灰色列表的对象,将其标记为黑色,并将其引用的所有对象标记为灰色,加入灰色列表。
- 所有对象标记完成后,设置当前白色为白色 2 。
- 遍历所有需要 gc 的对象,如果为白色 1 ,则该对象没有引用,直接清除。如果不为白色 1 ,则将该对象标记为白色 2 。
- 所有对象清除完成后,本轮 gc 结束。下轮 gc 则对白色 2 对象进行处理,两种白色交替使用。
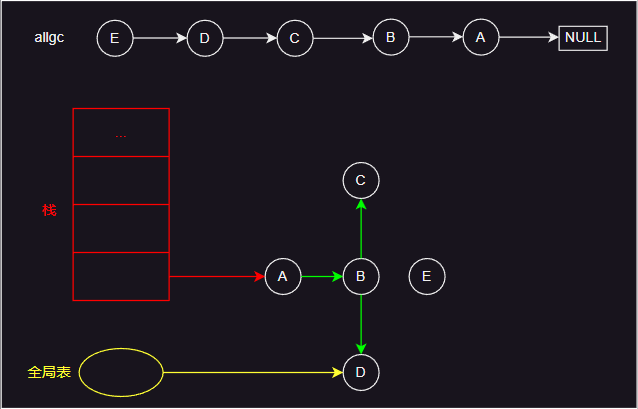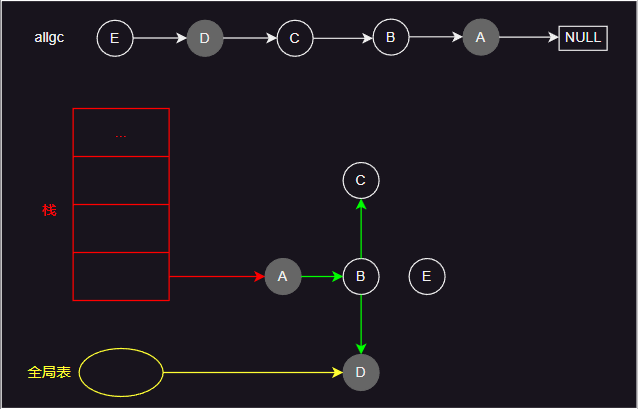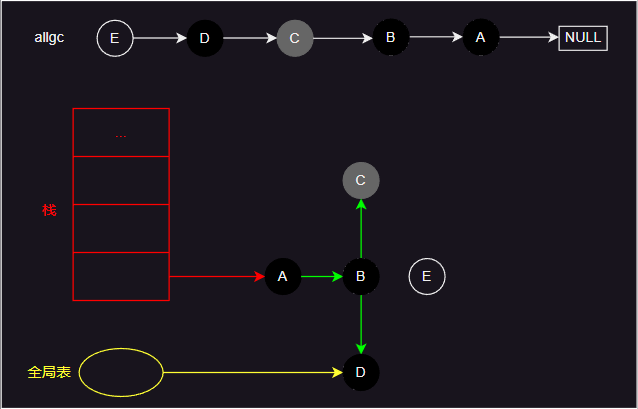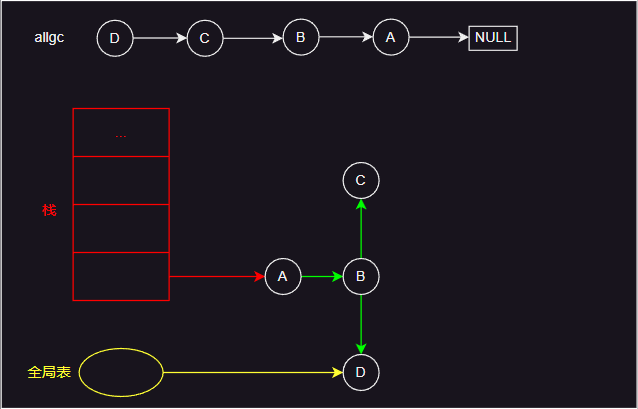
- 如上图所示,检查引用从栈和全局表开始,红色箭头表示栈引用的对象,黄色箭头表示全局表引用的对象,绿色箭头表示对象引用的其他对象。
- 标记开始时,引用的对象会被标记为灰色,然后下一步处理时变成黑色,并将其引用的对象标记为灰色。循环上面过程,直到将所有引用的对象标记完成。然后遍历 allgc 列表,白色的对象清除,其他对象则重新设置为白色。
- 简单来说,lua 的 gc 流程就如图中所示。实际上,lua 的 gc 过程分为几个阶段,具体实现中有许多细节内容。
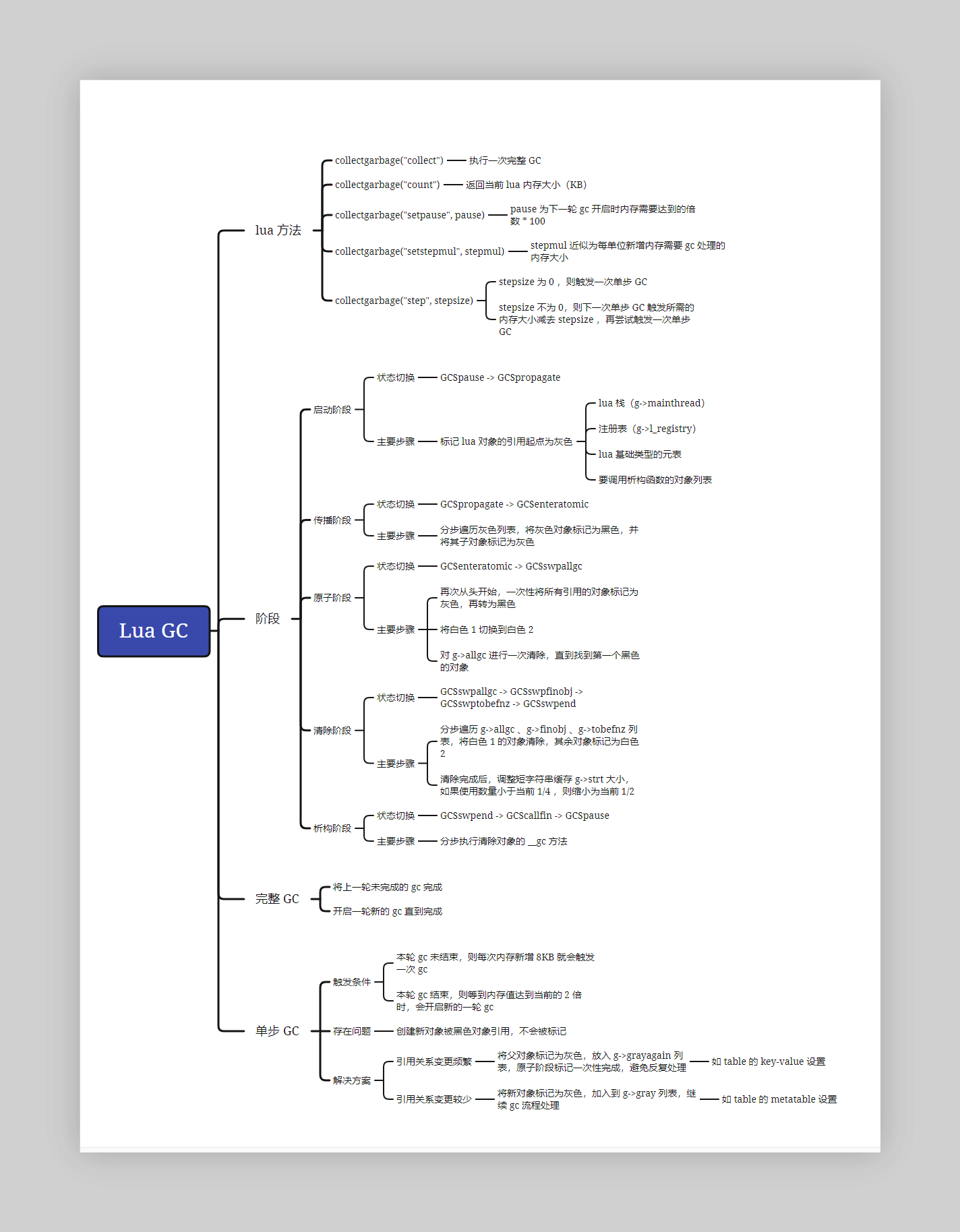
gc 阶段
- 初始化后,gcstate 为 GCSpause 状态,每个状态下 gc 执行步骤的代码为:
// lgc.c
static lu_mem singlestep (lua_State *L) {
global_State *g = G(L);
switch (g->gcstate) {
case GCSpause: {
restartcollection(g);
g->gcstate = GCSpropagate;
return 1;
}
case GCSpropagate: {
if (g->gray == NULL) { /* no more gray objects? */
g->gcstate = GCSenteratomic; /* finish propagate phase */
return 0;
}
else
return propagatemark(g); /* traverse one gray object */
}
case GCSenteratomic: {
lu_mem work = atomic(L); /* work is what was traversed by 'atomic' */
entersweep(L);
g->GCestimate = gettotalbytes(g); /* first estimate */;
return work;
}
case GCSswpallgc: { /* sweep "regular" objects */
return sweepstep(L, g, GCSswpfinobj, &g->finobj);
}
case GCSswpfinobj: { /* sweep objects with finalizers */
return sweepstep(L, g, GCSswptobefnz, &g->tobefnz);
}
case GCSswptobefnz: { /* sweep objects to be finalized */
return sweepstep(L, g, GCSswpend, NULL);
}
case GCSswpend: { /* finish sweeps */
checkSizes(L, g);
g->gcstate = GCScallfin;
return 0;
}
case GCScallfin: { /* call remaining finalizers */
if (g->tobefnz && !g->gcemergency) {
int n = runafewfinalizers(L, GCFINMAX);
return n * GCFINALIZECOST;
}
else { /* emergency mode or no more finalizers */
g->gcstate = GCSpause; /* finish collection */
return 0;
}
}
default: lua_assert(0); return 0;
}
}
启动阶段(GCSpause -> GCSpropagate)
- 启动阶段主要执行的代码如下:
// lgc.c
static void restartcollection (global_State *g) {
cleargraylists(g);
markobject(g, g->mainthread);
markvalue(g, &g->l_registry);
markmt(g);
markbeingfnz(g); /* mark any finalizing object left from previous cycle */
}
- 启动阶段也是 gc 循环开始的阶段,主要是将 lua 对象引用的起点进行标记,其步骤为:
- 清除 gc 循环过程中记录的链表(g->gray 、g->grayagain 、g->weak 、g->allweak 、g->ephemeron)。
- 将 lua 栈(g->mainthread)标记为灰色。
- 将注册表(g->l_registry)的标记为灰色。
- 将 lua 基础类型的元表标记为灰色。
- 将要执行析构方法的列表(g->tobefnz)的所有对象标记为灰色。
- 其中,标记的方法具体实现为:
// lgc.c
static void reallymarkobject (global_State *g, GCObject *o) {
switch (o->tt) {
case LUA_VSHRSTR:
case LUA_VLNGSTR: {
set2black(o); /* nothing to visit */
break;
}
case LUA_VUPVAL: {
UpVal *uv = gco2upv(o);
if (upisopen(uv))
set2gray(uv); /* open upvalues are kept gray */
else
set2black(o); /* closed upvalues are visited here */
markvalue(g, uv->v); /* mark its content */
break;
}
case LUA_VUSERDATA: {
Udata *u = gco2u(o);
if (u->nuvalue == 0) { /* no user values? */
markobjectN(g, u->metatable); /* mark its metatable */
set2black(o); /* nothing else to mark */
break;
}
/* else... */
} /* FALLTHROUGH */
case LUA_VLCL: case LUA_VCCL: case LUA_VTABLE:
case LUA_VTHREAD: case LUA_VPROTO: {
linkobjgclist(o, g->gray); /* to be visited later */
break;
}
default: lua_assert(0); break;
}
}
static void linkgclist_ (GCObject *o, GCObject **pnext, GCObject **list) {
lua_assert(!isgray(o)); /* cannot be in a gray list */
*pnext = *list;
*list = o;
set2gray(o); /* now it is */
}
/*
** Link a generic collectable object 'o' into the list 'p'.
*/
#define linkobjgclist(o,p) linkgclist_(obj2gco(o), getgclist(o), &(p))
- 可以看到,通常情况下,标记灰色的过程为:
- 将当前对象的 gclist 指向灰色对象列表 gray 。
- 将当前对象设置到 gray 列表。
- 将当前对象标记为灰色(非黑非白)。
- 而对于字符串类型,则是直接将对象标记为黑色。这是因为字符串类型的对象,不会再引用其他的对象,所以不需要再向后延伸。
传播阶段(GCSpropagate -> GCSenteratomic)
- 传播阶段的代码实现为:
// lgc.c
static lu_mem propagatemark (global_State *g) {
GCObject *o = g->gray;
nw2black(o);
g->gray = *getgclist(o); /* remove from 'gray' list */
switch (o->tt) {
case LUA_VTABLE: return traversetable(g, gco2t(o));
case LUA_VUSERDATA: return traverseudata(g, gco2u(o));
case LUA_VLCL: return traverseLclosure(g, gco2lcl(o));
case LUA_VCCL: return traverseCclosure(g, gco2ccl(o));
case LUA_VPROTO: return traverseproto(g, gco2p(o));
case LUA_VTHREAD: return traversethread(g, gco2th(o));
default: lua_assert(0); return 0;
}
}
- 该阶段执行一次,会将灰色列表的当前对象移除,标记为黑色,并将此对象的 gclist 设置为灰色列表(和启动阶段的设置对应)。之后,对此对象进行遍历,获取其引用的所有对象,标记成灰色,加入灰色列表。
- 此后,会重复上面的过程,持续标记过程,直到灰色列表的所有对象都已经标记为黑色,该阶段才算真正完成。
遍历 table
- 遍历检查 table 过程如下:
// lgc.c
static lu_mem traversetable (global_State *g, Table *h) {
const char *weakkey, *weakvalue;
const TValue *mode = gfasttm(g, h->metatable, TM_MODE);
markobjectN(g, h->metatable);
if (mode && ttisstring(mode) && /* is there a weak mode? */
(cast_void(weakkey = strchr(svalue(mode), 'k')),
cast_void(weakvalue = strchr(svalue(mode), 'v')),
(weakkey || weakvalue))) { /* is really weak? */
if (!weakkey) /* strong keys? */
traverseweakvalue(g, h);
else if (!weakvalue) /* strong values? */
traverseephemeron(g, h, 0);
else /* all weak */
linkgclist(h, g->allweak); /* nothing to traverse now */
}
else /* not weak */
traversestrongtable(g, h);
return 1 + h->alimit + 2 * allocsizenode(h);
}
- 对于 table 来说,根据 table 是否为弱表,有不同的检查方式。
- key 为强类型,value 为弱类型。
- 遍历 table 的哈希表部分,如果 value 为空,则清除 key 值。如果 value 不为空,则将 key 值标记为灰色。
- 如果当前是在 GCSatomic 状态,并且数组部分不为空,或者哈希表部分存在未标记的对象,则该 table 要加入到 g->weak 列表中,不然就将 table 加入到 g->grayagain 列表中。
- key 为弱类型,value 为强类型。
- 遍历 table 的数组部分,将所有对象标记为灰色。
- 遍历 table 的哈希表部分:
- 如果 value 为空,则清除 key 值。
- 如果 value 不为空,key 已标记,value 未标记过,则将 value 值标记为灰色。
- 如果当前为 GCSpropagate 状态,则将 table 加入 g->grayagain 列表。
- 如果遍历前存在 key-value 都未标记过的,则将 table 加入 g->ephemeron 列表。
- 如果遍历前存在 key 未标记过的,则将 table 加入 g->allweak 列表。
- key-value 都为弱类型。 -将 table 加入 g->allweak 列表。
- key-value 都为强类型。
- 遍历 table 的数组部分,将所有对象标记为灰色。
- 遍历 table 的哈希表部分:
- 如果 value 为空,则清除 key 值。
- 将 key 值标记为灰色。
- 将 value 值标记为灰色。
- key 为强类型,value 为弱类型。
- 遍历结束后,会返回处理的 TValue 对象数量,为:
- 当前 table :1 。
- table 的数组部分数量: h->alimit 。
- table 的哈希表部分数量(每个节点有 key 和 value 两个对象):2 * allocsizenode(h) 。
遍历 thread
- 遍历检查 thread 过程如下:
// lgc.c
static int traversethread (global_State *g, lua_State *th) {
UpVal *uv;
StkId o = th->stack;
if (isold(th) || g->gcstate == GCSpropagate)
linkgclist(th, g->grayagain); /* insert into 'grayagain' list */
if (o == NULL)
return 1; /* stack not completely built yet */
lua_assert(g->gcstate == GCSatomic ||
th->openupval == NULL || isintwups(th));
for (; o < th->top; o++) /* mark live elements in the stack */
markvalue(g, s2v(o));
for (uv = th->openupval; uv != NULL; uv = uv->u.open.next)
markobject(g, uv); /* open upvalues cannot be collected */
if (g->gcstate == GCSatomic) { /* final traversal? */
StkId lim = th->stack + th->stacksize; /* real end of stack */
for (; o < lim; o++) /* clear not-marked stack slice */
setnilvalue(s2v(o));
/* 'remarkupvals' may have removed thread from 'twups' list */
if (!isintwups(th) && th->openupval != NULL) {
th->twups = g->twups; /* link it back to the list */
g->twups = th;
}
}
else if (!g->gcemergency)
luaD_shrinkstack(th); /* do not change stack in emergency cycle */
return 1 + th->stacksize;
}
- 对于线程类型对象,主要操作对象为栈和 upvalue ,过程为:
- 从栈底到栈顶,把栈上的对象标记为灰色。
- 将 openupval 列表的对象标记为灰色。
- 如果当前是 GCSatomic 状态,从栈顶开始,到整个栈的最大值,将栈上所有对象清除。
- 如果当前不为 GCSatomic 状态,且 g->gcemergency 不为 0(即不为紧急 gc),则对当前栈进行缩减,缩减流程为:
- 获取当前栈正在使用的大小。
- 设置最佳大小为正在使用的大小加上 BASIC_STACK_SIZE(C 函数可用的最小 lua 栈大小的 2 倍,20)。
- 如果当前正在使用的大小没有超过 LUAI_MAXSTACK - EXTRA_STACK,并且最佳大小也小于当前栈的大小,才以最佳大小进行栈缩小。
- 遍历结束后,返回处理的大小为:
- 当前 thread 对象 :1 。
- 当前栈的大小:th->stacksize 。
原子阶段(GCSenteratomic -> GCSswpallgc)
- 原子阶段主要从头开始,对所有未标记过的对象进行检查标记,再执行一次清扫过程。
- 该阶段的标记方法为:
// lgc.c
static lu_mem atomic (lua_State *L) {
global_State *g = G(L);
lu_mem work = 0;
GCObject *origweak, *origall;
GCObject *grayagain = g->grayagain; /* save original list */
g->grayagain = NULL;
lua_assert(g->ephemeron == NULL && g->weak == NULL);
lua_assert(!iswhite(g->mainthread));
g->gcstate = GCSatomic;
markobject(g, L); /* mark running thread */
/* registry and global metatables may be changed by API */
markvalue(g, &g->l_registry);
markmt(g); /* mark global metatables */
work += propagateall(g); /* empties 'gray' list */
/* remark occasional upvalues of (maybe) dead threads */
work += remarkupvals(g);
work += propagateall(g); /* propagate changes */
g->gray = grayagain;
work += propagateall(g); /* traverse 'grayagain' list */
convergeephemerons(g);
/* at this point, all strongly accessible objects are marked. */
/* Clear values from weak tables, before checking finalizers */
clearbyvalues(g, g->weak, NULL);
clearbyvalues(g, g->allweak, NULL);
origweak = g->weak; origall = g->allweak;
separatetobefnz(g, 0); /* separate objects to be finalized */
work += markbeingfnz(g); /* mark objects that will be finalized */
work += propagateall(g); /* remark, to propagate 'resurrection' */
convergeephemerons(g);
/* at this point, all resurrected objects are marked. */
/* remove dead objects from weak tables */
clearbykeys(g, g->ephemeron); /* clear keys from all ephemeron tables */
clearbykeys(g, g->allweak); /* clear keys from all 'allweak' tables */
/* clear values from resurrected weak tables */
clearbyvalues(g, g->weak, origweak);
clearbyvalues(g, g->allweak, origall);
luaS_clearcache(g);
g->currentwhite = cast_byte(otherwhite(g)); /* flip current white */
lua_assert(g->gray == NULL);
return work; /* estimate of slots marked by 'atomic' */
}
- 可以看到,该阶段的标记过程,还是从 lua 栈、注册表、基础类型元表为起点进行检查标记。传播阶段中的 g->grayagain 、g->ephemeron 会在这个全部进行遍历标记,g->weak 、g->allweak 弱表列表,也会在这个阶段进行清除。
- 完成所有标记操作后,会将 g->currentwhite 切换为另一种白色,在这之后新建的对象,则不会在这轮 gc 中处理。
- 和传播阶段相比,原子阶段的标记操作是一步到位的,需要将所有对象都标记完成,才会执行其他操作,这个过程不能中断。
- 完成标记后,会执行清除阶段的准备过程。
// lgc.c
static void entersweep (lua_State *L) {
global_State *g = G(L);
g->gcstate = GCSswpallgc;
lua_assert(g->sweepgc == NULL);
g->sweepgc = sweeptolive(L, &g->allgc);
}
static GCObject **sweeptolive (lua_State *L, GCObject **p) {
GCObject **old = p;
do {
p = sweeplist(L, p, 1, NULL);
} while (p == old);
return p;
}
- 进入清除阶段前,会对 g->allgc 进行清除处理,直到找到第一个还有引用的对象,转为白色后,将其下一个对象设置到 g->sweepgc 上。经过一次清除处理后到进入清除阶段之间创建的新对象,就能直接跳过,因为这些在标记结束后的新对象需要在下一轮 gc 中才会处理,避免占用本轮 gc 处理的对象数量。
清除阶段(GCSswpallgc -> GCSswpfinobj -> GCSswptobefnz -> GCSswpend)
- 清除阶段主要对几个列表处理,包括 g->allgc 、g->finobj 、g->tobefnz。对 g->sweepgc 进行清除后,再依次将下一个列表设置到 g->sweepgc ,继续处理。清除的代码如下:
// lgc.c
static int sweepstep (lua_State *L, global_State *g,
int nextstate, GCObject **nextlist) {
if (g->sweepgc) {
l_mem olddebt = g->GCdebt;
int count;
g->sweepgc = sweeplist(L, g->sweepgc, GCSWEEPMAX, &count);
g->GCestimate += g->GCdebt - olddebt; /* update estimate */
return count;
}
else { /* enter next state */
g->gcstate = nextstate;
g->sweepgc = nextlist;
return 0; /* no work done */
}
}
static GCObject **sweeplist (lua_State *L, GCObject **p, int countin,
int *countout) {
global_State *g = G(L);
int ow = otherwhite(g);
int i;
int white = luaC_white(g); /* current white */
for (i = 0; *p != NULL && i < countin; i++) {
GCObject *curr = *p;
int marked = curr->marked;
if (isdeadm(ow, marked)) { /* is 'curr' dead? */
*p = curr->next; /* remove 'curr' from list */
freeobj(L, curr); /* erase 'curr' */
}
else { /* change mark to 'white' */
curr->marked = cast_byte((marked & ~maskgcbits) | white);
p = &curr->next; /* go to next element */
}
}
if (countout)
*countout = i; /* number of elements traversed */
return (*p == NULL) ? NULL : p;
}
- 清除的步骤为,检查每个对象的标记:
- 如果为白色,则表示该对象已经没有引用,将对象释放,并将 g->GCdebt 减去该对象释放的大小。
- 如果不为白色,则将该对象的标记设置为新的白色。
- 每次清除的最大数量为 100 (GCSWEEPMAX)个对象,当前列表完全清除后,才会进入下一个状态清除下一个列表。
- 所有列表清除完成后,就切换到 GCSswpend 状态,此时会进行字符串缓存的检查。
// lgc.c
static void checkSizes (lua_State *L, global_State *g) {
if (!g->gcemergency) {
if (g->strt.nuse < g->strt.size / 4) { /* string table too big? */
l_mem olddebt = g->GCdebt;
luaS_resize(L, g->strt.size / 2);
g->GCestimate += g->GCdebt - olddebt; /* correct estimate */
}
}
}
- 常规 gc 时,g->strt.nuse 为字符串缓存表当前 TString 的数量,如果小于当前大小的 1/4 ,则需要将 strt 缩小为当前大小的 1/2 ,
析构阶段(GCSswpend -> GCScallfin -> GCSpause)
- 析构阶段主要是对 g->tobefnz 列表的,执行析构函数(即元表的 __gc 方法),每个析构函数等价于 50(GCFINALIZECOST)个 TValue 处理对象。
- 处理完成后,就切换到 GCSpause 状态,本次 gc 循环结束。
完整 GC
- 一次完整的 GC ,可以通过调用 lua 提供的 collectgarbage(“collect”) 方法实现。
// lgc.c
static void fullinc (lua_State *L, global_State *g) {
if (keepinvariant(g)) /* black objects? */
entersweep(L); /* sweep everything to turn them back to white */
/* finish any pending sweep phase to start a new cycle */
luaC_runtilstate(L, bitmask(GCSpause));
luaC_runtilstate(L, bitmask(GCScallfin)); /* run up to finalizers */
/* estimate must be correct after a full GC cycle */
lua_assert(g->GCestimate == gettotalbytes(g));
luaC_runtilstate(L, bitmask(GCSpause)); /* finish collection */
setpause(g);
}
- 当调用一次完整 GC 时,操作流程如下:
- 如果当前状态在 GCSatomic 之前,即还未开始原子阶段的清除操作,则会进行原子阶段的清除操作。
- 将当前 gc 持续执行,直到当前状态为 GCSpause ,即完成上一轮未结束的 gc 。
- 再重新触发 gc ,同样执行到这一轮 gc 结束。
- 可以看到,一次完整的 GC ,需要不间断地完成上一轮和新的一轮操作,这个过程耗时将会随着内存增大而增大。如果在使用过程中,每次 gc 都需要占用较长的一段时间,则会经常出现主线程卡住的情况。因此,lua 中采用了单步 GC ,来优化这种情况。
单步 GC
- lua gc 的各个阶段,每次执行都是一次单步 gc 的操作,单步 gc 通过调用 luaC_step 方法实现。单步 gc 的触发方式有:
- lua 中调用 collectgarbage(“step”) 方法。
- 部分操作完成后,调用 luaC_condGC 方法,尝试进行 gc 。相关的操作主要有:
- lua_tolstring :将栈上的 lua 值转为 c 字符串。
- lua_pushlstring :将指针指向的指定长度的字符串,转为 lua 字符串后入栈。
- lua_pushstring :将指针指向的以'\0’结尾的字符串,转为 lua 字符串后入栈。
- lua_pushvfstring/lua_pushfstring :将格式化后的字符串,转为 lua 字符串后入栈。
- lua_pushcclosure :创建一个 lua 闭包后入栈。
- lua_createtable :创建一个空表后入栈。
- lua_concat :字符串拼接。
- lua_newuserdatauv :创建 userdata 后入栈。
- …
- 可以看到,在 lua 中创建需要 gc 的对象时,就会尝试进行一次单步 gc 。因此,在整个 lua 运行过程,gc 的过程基本上是一直在背后不断进行的,通常不需要手动调用 collectgarbage(“collect”) 来进行垃圾回收。
触发条件
- luaC_condGC 的代码实现如下:
// lgc.h
#define luaC_condGC(L,pre,pos) \
{ if (G(L)->GCdebt > 0) { pre; luaC_step(L); pos;}; \
condchangemem(L,pre,pos); }
- 调用 luaC_condGC 方法时,并不是每次都会触发 luaC_step 方法进行单步 gc ,只有当 GCdebt > 0 时,gc 才会继续进行。而 GCdebt 的修改方式有:
- 创建新对象的时候,GCdebt 加上新增对象的大小。
- 释放对象的时候,GCdebt 会减去释放对象的大小。
- 执行 luaC_step 后,如果本轮 gc 没完成,则会修改 GCdebt 的值。
- GCdebt 修改的代码如下:
// lgc.c
static void incstep (lua_State *L, global_State *g) {
int stepmul = (getgcparam(g->gcstepmul) | 1); /* avoid division by 0 */
l_mem debt = (g->GCdebt / WORK2MEM) * stepmul;
l_mem stepsize = (g->gcstepsize <= log2maxs(l_mem))
? ((cast(l_mem, 1) << g->gcstepsize) / WORK2MEM) * stepmul
: MAX_LMEM; /* overflow; keep maximum value */
do { /* repeat until pause or enough "credit" (negative debt) */
lu_mem work = singlestep(L); /* perform one single step */
debt -= work;
} while (debt > -stepsize && g->gcstate != GCSpause);
if (g->gcstate == GCSpause)
setpause(g); /* pause until next cycle */
else {
debt = (debt / stepmul) * WORK2MEM; /* convert 'work units' to bytes */
luaE_setdebt(g, debt);
}
}
/*
** performs a basic GC step if collector is running
*/
void luaC_step (lua_State *L) {
global_State *g = G(L);
lua_assert(!g->gcemergency);
if (g->gcrunning) { /* running? */
if(isdecGCmodegen(g))
genstep(L, g);
else
incstep(L, g);
}
}
- 修改的过程为:
- 通过 g->GCdebt / WORK2MEM ,将当前的 GCdebt 值转化为 TValue 的数量,表示本轮 gc 需要处理的数量 debt 。
- 将上一步得到的 TValue 的个数,乘上 g->gcstepmul 倍数值,即将本轮 gc 处理的数量进行放大。
- 通过 cast(l_mem, 1) « g->gcstepsize 得到单步需要处理的大小,同样转化为 TValue 数量后再乘上倍数,表示单步 gc 处理的数量 stepsize。
- 执行 singlestep 方法,得到处理的 TValue 数量 work ,将 debt 减去 work ,重复执行,结束循环条件有两个:
- 当前状态为 GCSpause ,即本轮 gc 已经完成。
- 当前状态不为 GCSpause ,本次 gc 处理的对象已经达到上限,需要等下一次触发。
- gc 完成时,会调用 setpause 方法修改 g->GCdebt 的值,从而调整下一次 gc 触发的所需新增的内存值。
// lgc.c
static void setpause (global_State *g) {
l_mem threshold, debt;
int pause = getgcparam(g->gcpause);
l_mem estimate = g->GCestimate / PAUSEADJ; /* adjust 'estimate' */
lua_assert(estimate > 0);
threshold = (pause < MAX_LMEM / estimate) /* overflow? */
? estimate * pause /* no overflow */
: MAX_LMEM; /* overflow; truncate to maximum */
debt = gettotalbytes(g) - threshold;
if (debt > 0) debt = 0;
luaE_setdebt(g, debt);
}
- 新的 g->GCdebt 值为当前未释放的总大小减去阈值, 而阈值为 g->GCestimate / PAUSEADJ * pause ,其中:
- g->GCestimate 和 gettotalbytes(g) 一样,表示当前未释放的总内存。
- PAUSEADJ 默认值为 100 。
- pause 为 LUAI_GCPAUSE ,默认值为 200 。
- 因此,阈值为当前未释放总内存的两倍,则 g->GCdebt 会为当前未释放总内存的负数值,也就是说,下一次 gc 开始需要等到内存值达到当前的 2 倍。
- 当内存值较小时,单步 gc 通常能完成所有阶段。随着内存慢慢增大,单步 gc 只能处理一部分阶段,甚至只能处理一个阶段里的一部分对象。此时,每一步能处理的大小为 debt + stepsize ,其中:
- debt 为当前 g->GCdebt 转化为 TValue 个数后,放大 g->gcstepmul 的结果。
- stepsize 为 g->gcstepsize 转化为 TValue 个数后,放大 g->gcstepmul 的结果。
- 由于 g->GCdebt 是增加到正数时,就会触发 gc ,因此,此时的 g->GCdebt 通常为 1 个 TValue 大小的值,而 g->gcstepsize 为 8 KB 。相比较于 g->gcstepsize ,g->GCdebt 可以近似为 0,也就是说,每一步能处理的大小近似为 g->gcstepsize 放大 g->gcstepmul ,即 8KB * 100 。
- 当单步 gc 达到上限值后,同样会修改 g->GCdebt 的值,此时 debt 同样近似 -stepsize ,因此,g->GCdebt 会设置为近似 -8 KB ,即下一次 gc 开始需要等到内存值增加超过 8 KB。
- 可以看到,当单步 gc 无法完成一次完整 gc 时,可以近似认为,内存每增加 8 KB,就会处理 800 KB 的对象,也就是说,g->gcstepmul 代表了每单位新增内存需要 gc 处理的内存大小。
- 然而,当未释放的内存大小超过上限值的一半时,阈值会设置为内存上限值大小,从而 debt 会慢慢接近 0 ,即下次 gc 触发所需的内存增加值会越来越小,也就是说,gc 会越来越频繁。
- 总体来说,如果本轮 gc 未结束,则每次内存新增 8KB 就会触发一次 gc ,直到本轮 gc 结束,则等到内存值达到当前的 2 倍时,会开启新的一轮 gc 。
存在问题
- 一次完整的 gc ,其耗时会随着内存增大而增大,因为内存增大代表需要遍历处理的对象增多,为了避免 gc 引起阻塞,lua 中将 gc 设计成分步 gc 的形式。然而,分步同样也带来了新的问题。由于传播过程是分步执行的,每一步执行过后,都有可能会创建新的对象,并被某些对象引用,此时新对象会设置为白色。如果引用的对象为黑色,表示该对象已经标记完成,子对象也已经加入灰色列表,因此新对象将不会再被标记,在清除阶段,则会被当作不再引用的对象清掉。
- 为了避免出现这种问题,lua 提供了设置屏障的方法,来阻挡 gc 过程,保证新对象能够被正确处理,有两种屏障设置方法:
- luaC_barrier_
- luaC_barrierback_
// lgc.c
void luaC_barrier_ (lua_State *L, GCObject *o, GCObject *v) {
global_State *g = G(L);
lua_assert(isblack(o) && iswhite(v) && !isdead(g, v) && !isdead(g, o));
if (keepinvariant(g)) { /* must keep invariant? */
reallymarkobject(g, v); /* restore invariant */
if (isold(o)) {
lua_assert(!isold(v)); /* white object could not be old */
setage(v, G_OLD0); /* restore generational invariant */
}
}
else { /* sweep phase */
lua_assert(issweepphase(g));
if (g->gckind == KGC_INC) /* incremental mode? */
makewhite(g, o); /* mark 'o' as white to avoid other barriers */
}
}
void luaC_barrierback_ (lua_State *L, GCObject *o) {
global_State *g = G(L);
lua_assert(isblack(o) && !isdead(g, o));
lua_assert((g->gckind == KGC_GEN) == (isold(o) && getage(o) != G_TOUCHED1));
if (getage(o) == G_TOUCHED2) /* already in gray list? */
set2gray(o); /* make it gray to become touched1 */
else /* link it in 'grayagain' and paint it gray */
linkobjgclist(o, g->grayagain);
if (isold(o)) /* generational mode? */
setage(o, G_TOUCHED1); /* touched in current cycle */
}
- 其中,新对象 v 为白色,父对象 o 为黑色。
- luaC_barrier_ 方法,如果当前 gc 状态在 GCSatomic 之前,则将新对象标记为灰色,加入到 g->gray 列表中。如果已经进入清除阶段,则将父对象设置为白色。通常用于引用关系变化较少的情况,如: metatable 的创建和设置。
- luaC_barrierback_ 方法,则将父对象标记为灰色,加入到 g->grayagain 列表中。通常用于引用欢喜变化频繁的情况,如:table 的 key-value 对象创建修改。
- 当父对象已经为黑色时,为了避免新对象被清除,就需要通过 luaC_barrier_ 方法,将新对象也标记为灰色,进入到本轮 gc 标记处理过程。然而,这个新对象从灰色列表取出前,可能已经不被父对象引用,那这个新对象都不需要修改标记,只要保持白色等待被清除即可。
- 以 table 为例,当 table 被标记为黑色后,创建了一个新的对象 value1 ,设置到 table[key] 上,之后又创建了一个新对象 value2 ,设置到 table[key] 上。当这个过程非常频繁时,就会出现大量的对象加入到 g->gray 列表,增加了标记过程的持续时间。
- 为了避免这种情况,可以把新对象的父对象,即把 table 标记为灰色,加入到 g->gray 列表中,这样就只需要对 table 重新标记。然而,这种情况下,仍可能出现,table 刚从灰色标记为黑色,又因为引用关系修改,再标记为灰色,而后再标记为黑色,又因为引用关系修改,在黑色和灰色之间频繁变化。
- 基于这种情况,luaC_barrierback_ 方法将对象加入到 g->grayagain 列表中,而 g->grayagain 在原子阶段中,会将所有对象都处理完成后才会结束。g->grayagain 列表存放的对象表示会频繁变换标记颜色,如果对 g->grayagain 列表中的对象进行分步处理,则 g->grayagain 列表就会变成和 g->gray 列表一样,对象会反复在黑色和灰色之间变换,从而造成处理周期增长,影响性能。
- 因此,原子阶段是必不可少的。传播阶段尽可能将对象标记过程分摊成多次 gc 步骤,再由原子阶段不中断地将剩下所有对象标记完成,才能顺利过渡到清除阶段。
总结
- 总体来说,lua 的 gc 是优化版的标记清除算法,将一个庞大的 gc 过程拆分成多个小步骤,穿插在新对象创建的过程中处理,从而保证了 gc 在尽可能少占用主线程资源的情况下持续推进,实现较好的内存管理。然而,即便是再好的机制,也需要开发者遵循良好的使用规则,例如:尽量不要频繁创建大量的对象,全局表的对象不需要使用的时候进行删除(设置为 nil)等。